CS 111 - More on File Systems
Authors: Andre Encarnacao, Ignacio Zendejas, and Jordan Saxonberg
Date: November 22, 2005
Topics:
File System Organization
File System Consistency
File System Organization
Naming Schemes
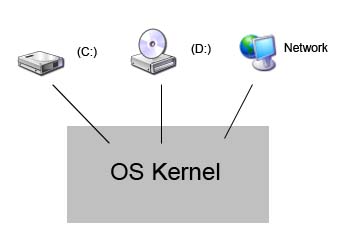
Fig. 1 - Disk setup
How do applications name all of these resources?
By using a naming scheme. Operating systems have different approaches on how these naming schemes are defined. Here are two examples:1. DOS uses a very familiar naming scheme. It uses letters to name drives, where each one of these drives is associated with a particular device and can possibly have its own file system. This sort of naming scheme is the equivalent of a forest structure of different file systems, as seen in figure 2 below.
The advantage, of course, is that the hardware is named, making the different devices distinguishable. However, it has some disadvantages:
- The names are only for the system's benefit, and not the user's benefit
-
There is limited space (up to 26 drives - one per letter)
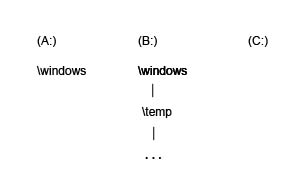
Fig. 2 - DOS Naming Scheme
Advantages of mounting:
- It's a user-oriented naming scheme
- It makes sense to be able to mount at any level (i.e., replace inodes at any level) and that's exactly what a mount enables one to do.
- The hardware is less obvious since devices can be located anywhere in the tree structure
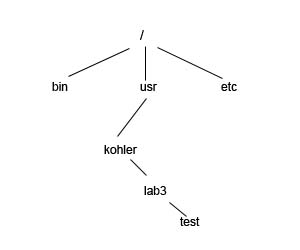
Fig. 3 - Linux Naming Scheme
Here's how we mounted OSPFS (our lab 3 file system):
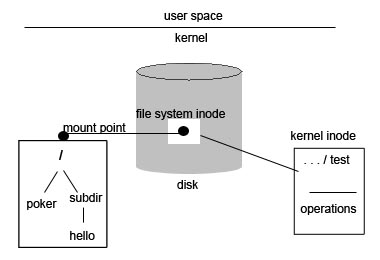
Fig. 4 - OSPFS (Lab 3 File System) Mounting
Open-File Guarantee
When can a kernel throw (i.e., garbage collect) a kernel structure (for example, a kernel inode)?
A kernel can garbage collect an inode when it is unreferenced. That is, when the following conditions are met:- No files associated with the inode are open
- None of its subdirectories are open
- None of the file components are open
test -> subdir -> Netscape
(You can't throw away subdir or test if Netscape is running.)
Now consider the case when you're updating Firefox on your Linux machine. When you update, /usr/bin/firefox gets overwritten with a newer version of /usr/bin/firefox. Imagine if there was no preservation of open files (i.e., open files can be modified when they are currently open or running) and we are updating Firefox while an instance of the program is currently running. In order to understand what may happen, we must first understand that when we run a program, we load the binary code into main memory. For programs that are huge like Firefox, we demand page them in the buffer cache. As we learned a few lectures ago, demand paging is when pages are loaded into memory only when needed. Figure 5 below shows this scenario.
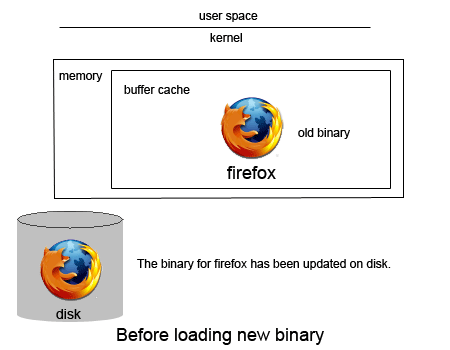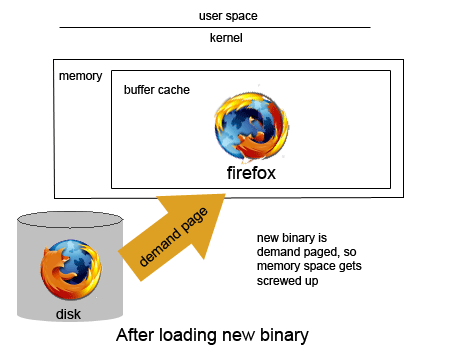
Fig.5 - Firefox references modified binary
Symbolic versus Hard Links
A hard link is when a directory entry refers to a particular file inode. Each file inode has at least one hard link or it wouldn't make sense. We usually say that a particular file is hard-linked if multiple directory entries in the file system refer to that file's inode. This means that the file is referenced by more than one directory (and therefore by more than one name). The problem here is that we cannot allow hard links to directories since this could create circular links and would violate the tree structure design of the file hierarchy, as discussed earlier. These circular links would also complicate garbage collection.How, then, is it possible for two directories to refer to just one directory as in the example below?
cd /home/kohlercd /u/idiots/kohler
We need to add a layer of indirection to permit the situation above and create a different type of link that does not change file system semantics. This new type of link is a symbolic link. A symbolic link is a special file type whose data contains a filename. This filename is essentially a "soft link" to another file. Whenever the kernel encounters a symbolic link file type, it reads the filename in the data part of the file and goes to that filename. It's as if the Kernel traverses the namespace for the user. Symbolic links are nice in that they are links at the namespace level rather than at the block level (like hard links). Figure 6 below shows what the symbolic link would look like for the example above.
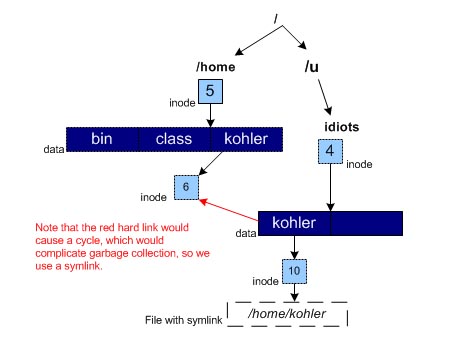
Fig. 6 - Symbolic Links
Figure 7 below illustrates the differences between hard links and symbolic links. For the hard link part, we assume that filenames a and c are hard linked to the same inode: A. When we delete filename a, inode A and file A do not get deleted since all we do is decrease the hard link count in that inode from 2 to 1. If we were to create a new file for filename a, then both the filenames (a and c) would reference two different file inodes (and therefore two different files). For the symbolic link part, we assume that filename c contains a symbolic link to filename a. When we delete filename a, inode A and file A get deleted as well and now the symbolic link is no longer valid and any reference to filename c will cause an error. This is the so-called dangling-link problem, where a symbolic link doesn't have any control over what happens with the file it's referencing. The file it points to can be deleted or its filename can change without the symbolic link file knowing what has happened. If we were to create a new file for filename a, then both the filenames (a and c) would still reference the same file inode and file (the one that was just created).
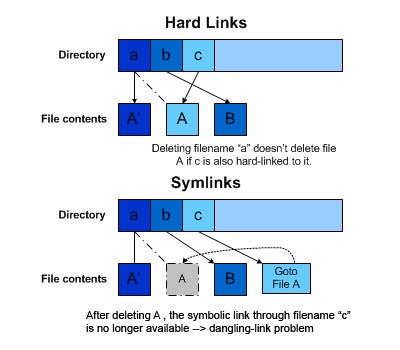
Fig. 7 - Hard Links vs. Symbolic Links
- Can link to directories without creating circular links (unlike hard links)
- Can link across file systems (unlike hard links)
- The dangling-link problem can occur
File System Correctness/Consistency
File System Correctness Problem
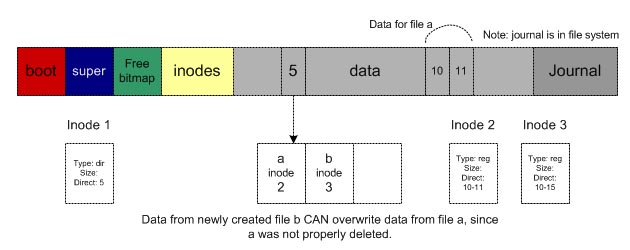
Fig. 8 - File system
- mark data blocks as free
- mark inode as free
- clear inode
- mark directory entry as unused
Invariants
Objective: A set of invariants that will ensure that the file system is in a consistent state.These are the invariants:
- No object is used for more than one purpose (No block belongs to more than one file as in the case described above).
- Every referenced block is marked allocated (No block is marked both free and used as in the case described above).
- Every unreferenced block is marked free (Otherwise, we get a disk leak, though less serious than the previous two invariants)
- Every referenced object (inode, block, et al) has been initialized (For example, if you point to an indirect block without having written to it, you may follow garbage pointers and encounter the case described above)
There are various ways for a file system to ensure consistency and, therefore, achieve robustness.
Here's how:
- File System Check (fsck in Unix) - works by verifying invariants listed above
- Runs after an unclean shutdown
- Traverses every directory and inode to cross-check against other inodes and directories, as well as the freemap block.
-
When it finds a problem, it fixes it. For example, for problems with files A and
B in figure 8, we could fix the problem by performing any one of these
actions:
- Delete file A
- Delete file B
- Copy double-used block so we have 2 separate copies (but keep in mind that we can't preserve the data for both files A and B)
- Disadvantage: File System Check is just a "band-aid" to place the file system in a consistent state. It has to guess the correct state of the file system and it often guesses wrong. This is problematic.
- Disadvantage: VERY SLOW!!!
- Careful Ordering (Synchronous Metadata)
- Order all updates to file system structure in such a manner that only the third invariant may be violated (the invariant that states that every unreferenced block is marked free). This invariant is not as serious as the others since it can only cause disk leaks, but it cannot cause corruption. For example, for unlinking a file, if we follow the steps listed earlier in the notes in the opposite order (starting at step 4 and going up to step 1), then we can ensure that only the 3rd invariant can be violated.
- Disadvantage: This method requires synchronous writes to disk so we cannot take advantage of many of the nice efficiency-increasing techniques we've previously discussed. This includes use of the buffer cache (for page swapping), page pre-fetching and the disk scheduling algorithms. This is all because writes to the disk NEED to occur in a certain order so that we can ensure that only the 3rd invariant may be violated.
- Journaling - File System Transactions
- The main idea is to keep a log of all the disk transactions (consisting of a few disk operations), and to only write to the file system structures when that particular transaction commits (commit - the atomic point when the transaction becomes persistent). Then, whenever the system reboots, we can just replay the log to make sure that every committed transaction was actually performed. If a certain recorded log transaction was not completed because of a system crash, then we can go ahead and complete the transaction.
- This log/journal is usually kept in a special section of the file system (see figure 8 above) and is available for viewing on Linux machines at /.journal. Note: typical journals are about 2 MB in size.
- Here are the steps taken when a file system is performing some operations that constitute a "transaction":
- Write the transaction contents to the journal (see figure 9 below for a sample journal transaction for deleting a file)
- Perform the operations of the transaction to the actual file system
- Mark the transaction as done by writing commit to the journal (this means that the transaction has been committed to the file system)
- When the system reboots, we run through the journal and make sure that every committed transaction was actually performed and is on disk. Once a transaction has been checked, it can be marked as "released"
- This method is slow because we need to write both the journal and the disk, but the advantage is that we have a contiguous arrangement of journal transactions and this means that there are fewer seeks when we are verifying that transactions were actually performed.
- We have two options for what sort of data to store in the journal:
- Write just the operation name (this is just a handful of bytes per operation)
- Write the entire block that was modified. This is actually necessary since writing blocks is not an atomic operation in the hardware. What if the system crashes while the hardware is midway through writing a block into disk? We need to be able to recover from this and storing the entire block in our journal is a way to do this. This approach makes non-atomic hardware appear atomic! The ext3 file system in Linux uses this approach.

Fig.9 - Journaling Transaction