Scribe Notes for Tuesday of 10th week, 12/6/2005
by Howard Hwa, Brian Kennedy, Ken Myers, and
Robert Wei
v1.50, 12/11/2005
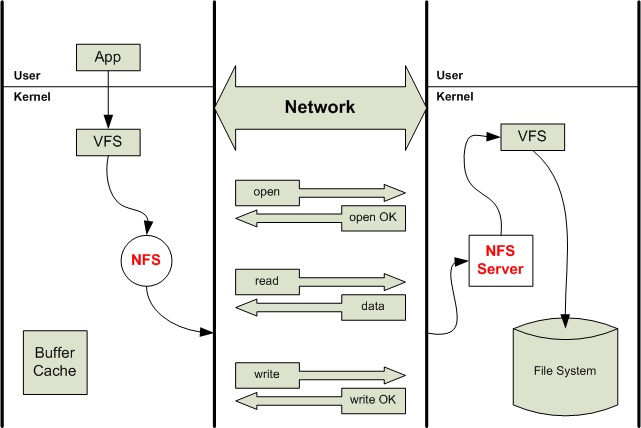
Distributed File Systems
Distributed file systems make files on one
computer accessible over the network to other computers
- An example: Sun's NFS network file system
- Provide, if possible, the same semantics as a local file system.
As we can see from the above diagram:
- NFS (network file system) converts
user-level command to RPC
- NFS server reverses the process, converts
RPC to user-level command
Performance
Network setting adds latency because of the
round-trip time of each RPC.
This latency can be avoided with prefetching and caching.
However, a problem arises from this:
Cache is a local snapshot of the system's persistent
state
So, since there are multiple clients, snapshots will be out of date.
Latency itself can already cause problem:
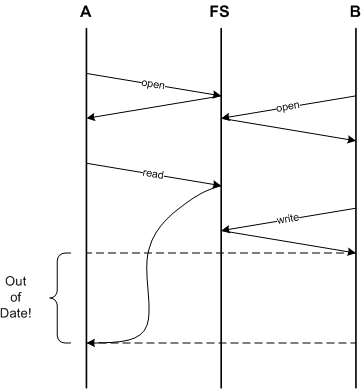
Instead of improving the situation, caching
instead makes it worse!
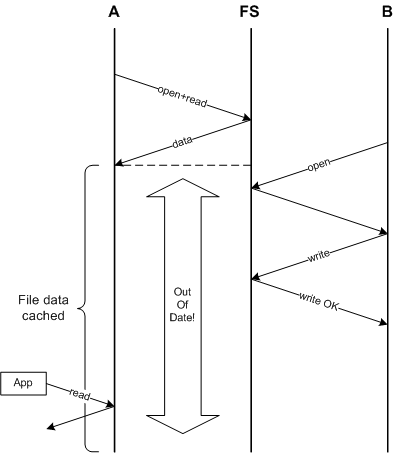
It is being out of date for a even longer time!
***Fundamentally, caching is in conflict with consistency!***
How to fix it:
Local file system has write-to-read consistency.
For network file system, we can have close-to-open consistency.
(note: NOT close-to-read!!!)
Implementation of Close-to-Open:
Open file: cache some portion of the data
Read: Cache, or RPC on cache miss
Write: write to cache
Close: flash write to server, close RPC, clear cache of data for this
file
The diagram below may clarify things.
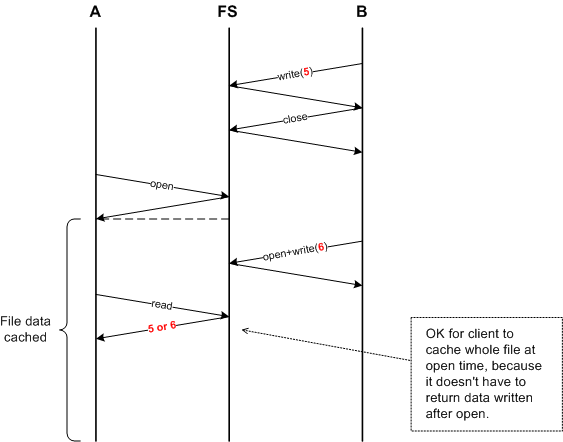
If we use RPC's getattr call, the
implementation will be easier because it includes version number of the file.
How the implementation will be changed:
- When open file, if getattr tells us that the file is different, we first flush
cached data, then read cache. If the file is same, we do nothing.
- We don't need to clear the cache of data at the end of closing file anymore,
since it will be taken care of when the file is opened.
Protocol Design
NFS is designed as a stateless protocol.
So, server keeps no per-client state, and every RPC executes atomicaly and
contains all state necessary to perform RPC (that is, authentication
information, file data, etc.)
This makes it immune to denial-of-service attacks.
Its design must be robust. There should be no problem when client crashes or
when server reboots.
There are no file descriptors; instead, there are file handles, which are
64-bit numbers identifying files (not filenames). As a result, instead of
"open", NFS has "lookup" for file handles.
If we update the protocol to notify on change, its advantage of being stateless will no longer hold; it now maintains per-client state. On the other hand, the consistency will be better, since there will be no state data caching.
Example: Andrew File System (AFS)
AFS provides clients with leases, which include a
time limit saying howlong the server will continue to notify clients with updates.
So, what can be a file handle? Is it an inode
number? a hash or filename?
*** File handle should be unpredictable
=> Clients can't guess it
=> Valid file handle was returned from lookup RPC
=> Sufficient to put authentication information on lookup RPC
only
Security & Protection
-----------------------------------------------------------------------------------------------------------------------------------------Goal: Prevent unauthorized
access to resources
Ensure
authorized access to resouces
These are negative goals.
- Positive goal: Any solution is sufficient
- Negative goal: Prevent every attack
This now leads to authorization, but
let's define a few terms first.
Principal: who is trying to do something?
Access right: what is principal trying to do?
Object/Resource: what object is principal trying to affect?
Example: Process P (principal) is trying to read (access
right) file /etc/passwd (object).
To define a security policy:
1) Enumerate principals
2) Enumerate access rights
3) Enumerate objects
4) Define an access matrix that says which principal-onject-access
rights are authorized.
Example: Process kill() and wait()
System with 4 processes
P0, P1, P2
===> user U; P0 is parent of P1
P3
===> user V
The top row is object; the left column is principal.
| P0 | P1 | P2 | P3 | |
| P0 | kill | wait kill |
kill | |
| P1 | kill | kill | kill | |
| P2 | kill | kill | kill | |
| P3 | kill |
Large access matrix:
=> specific policies
=> expensive to implement
=> hard to define policies
However, that does not make a smaller access
matrix better!
Small access matrix is easier to fall for buffer overflow!
A simple buffer overflow bug:
| int newconn(int fd) { char buf[1024]; int pos = 0; while ( (r = read(fd, &buf[pos], 1)) == 1 ) pos++; buf[pos] = 0; } |
This will allow an attacker to control what code is run next.
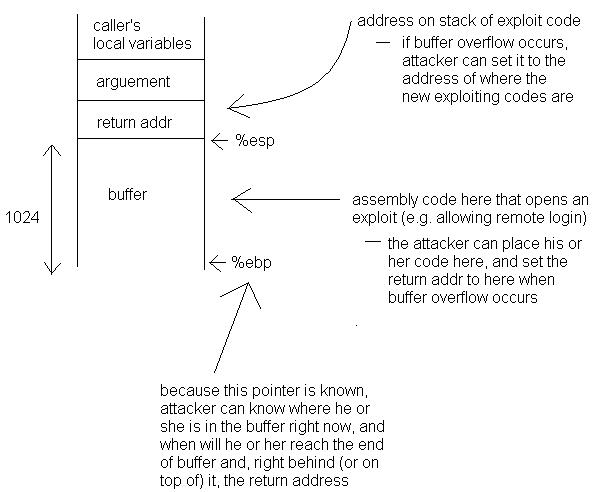
Why do buffer overflows cause large breaches of security? Maybe people should start practicing principle of least privilege more.
POLP: Principle of Least Privilege
- Every subject / application should have the minimum privilege required to
accomplish its function