CS
111
Scribe
Notes: Lecture 11
by Kathy Lee, Alex Pesterev, Hyduke Noshadi, Shaun Ahmadian
Memory and I/O
First, let's revisit the copy-on-write mechanism we talked about last time, in the context of memory-mapped I/O. Copy-on-write is a lot more important than just for memory-mapped files!
Let's consider how a fork will work in a paged memory environment. The parent process virtual memory will look some thing like this:
![]()
The resulting child after the fork should also have exactly the same virtual memory as above. So, since the parent's virtual memory is composed of a set of pages, lets copy each page associated with the parent, group all these pages in exactly the same virtual memory ordering as the parent and call it the child process. This will work and is called “eager copying” - all pages are copied to the child on the fork call.
We can, however, see some room for optimization. We know that the “Text” region of virtual memory is read only, therefore, we can share it between the two process, and with the help of virtual memory, virtual address space, and paging, we can share this data - the address space of the program text in the child and the parent will point to the same physical pages in memory.
We can take this approach a step further: why not share all of the underlying physical pages of the two processes? The problem with this approach is that if one of the processes tries to modify its data, then the memory of the other process will be inconsistent. To solve this problem, we can you use the copy-on-write service provided by memory paging (we will specifically use the write/read bits in the page table entries). The fork function will have to do something like this:
- create a virtual memory space for the child node and point the virtual memory to the parents physical pages
- mark all pages as read only
After this simple fork, the two processes are allowed to run. If neither of the process modify the physical pages, the two continue to share the same pages. However, as soon as one of the processes tries to modify the data in a page, a page fault will occur (the pages are set as read only but a write takes place). The page handler will realize that the page fault occurred because of shared physical memory and will:
- copy the single page where the write was attempted to another place in memory (resulting in two copies of the same page)
- modify the virtual memory, of the process attempting to do a write, to point to the new page
- mark the two identical pages as writable, and return control to the callee
This strategy allows us to share as much data across multiple forked children as possible. In this manner we significantly increase the amount of available memory. Forking in this manner is called “lazy copying,” because no copying is done until it is definitely required.
The Cost of Eager vs. Lazy Copying
The lazy copy, however, is not the perfect solution. Depending on the process characteristics, lazy copying may not be the best solution. For example, what if the forked child needs to modify all the physical pages? Under lazy copying, there will be a page fault for every writable page in memory; these page faults will get expensive. The eager copy, on the other hand, will copy all of the memory and will thus bypass the page faults. In general here is the cost model of eager vs.lazy copying:
|
Eager |
Lazy |
|
N * C |
W * (F + C) |
N = number of pages
W = number of pages that will be
written
C = cost of page copy
F = cost of page fault
From the table, it is obvious that the more W pages, the slower the lazy copy will get because it incurs both a C cost and a F cost.
Demand Paging
A variation of lazy copying is called demand paging. Demand paging applies to programs being loaded into memory for execution; parts of a program are lazily loaded into memory just like pages are lazily copied during a fork. A small subset of pages that are vital to a programs execution are loaded into memory and the rest are marked “not present” (remember that there is a present bit in a page table entry that is used for exactly this purpose). If a program uses only the pages that have been initially loaded into memory, then there will be no need to further load pages from disk. However, if a program decided to execute code or use data that is not in memory, a page fault will occur. The page fault will do something like this:
- if the page is not in memory and is a demand page then load the page into memory (note that this is a BLOCKING call)
- clear the present bit
- return control to callee
Demand paging is a nice way of reducing the initial load burden by loading large programs in parts; however, this benefit can also be a great bottleneck during execution. Loading a program page-by-page is slow and expensive, if a program consistently tries to access pages that are not yet loaded, then runtime will greatly slow down for every page load. To help solve this problem we can use prefetching.
Prefetching
As soon as the core of a program is loaded into memory, it begins execution; in the background the operating system prefetches other pages into memory while the process runs, hence eliminating blocking cost. This approach allows a program to load faster and also execute faster.
For prefetching to be effective, the OS needs to fetch the pages that are most relevant to the programs execution. There are a couple ways to notify the OS which pages to load into memory next:
- have the program be profiled and load pages according to this profile The problem with this approach is that a profile will be effective only when the programs are repetitive and always execute exactly the same way. If anything changes that is outside the norm, the profile will not be able to foreshadow page use.
- have the complier or the program give hints to the OS as to what to load
- locality of reference
Locality
of reference refers to loading pages into memory that are in close proximity to
the page that is currently being used by the process. This idea is based on the
fact that program execution is usually local and thus page loads that are local
will be most beneficial to execution speed.
Swapping
Up to this point we have assumed that our programs/processes could all exist within the physical memory. However, like it is in most cases, memory requirements of all active processes are larger than main memory. Hence we are forced to move some pages out of main memory and move others in.
The following is a simplified version of the page fault algorithm we could use:
· if a page P is “not present” and the page was swapped out choose a some other page to swap out
· load page P from disk
· when the page is swapped in resume process with the page marked “present” in VA.
In swapping pages of one process for pages of another process, the OS must follow some set criteria. Although there are many policies that exist, here are some basic considerations in making such a policy:
· Fairness – each processes should have an opportunity to be run on the CPU
· Size – processes with smaller page requirements would be easier and faster to swap out.
·
State of
· Priority – higher priority jobs should not be swapped out (especially those that rely on real-time interaction)
Sometimes it reaches a point that the CPU is spending more time paging than executing and this known as thrashing. Typical causes of thrashing are:
· Bad page swapping algorithm
· There are too many processes running on the machine.
Page Replacement Algorithms
So far we have been discussed about paging and assumed that each page fault at most once. However, what happens if there is no free frame to allocate? Page replacement to the rescue—why not choose a page that will be accessed farthest into the future and swap it out, hence creating a free frame. The goal is to have a lowest page fault rate which means having the minimum number of swaps.
There are several page replacement algorithms:
- First In First Out (FIFO)
This is the simplest page replacement algorithm. The victim is the oldest page in memory. It is like locality because newer pages are more “local.” FIFO focuses on the length of time a page has been in memory rather than how much the page is being used. Its advantage is that it is simple to implement; however, its behavior is not particularly well suited to the behavior of most programs.
For instance, an event-loop like the one below would perform terribly under FIFO! The code returns to the event loop after every event, so it is a mistake to swap out the event loop code itself. But that code will always get swapped out sooner or later, because eventually it will age to being the oldest page in the queue!
While (next event)
Process
event
Assume there are four frames and following reference string:
1-5 : reference string
f : page fault
|
1 |
2 |
3 |
2 |
4 |
3 |
5 |
1 |
5 |
2 |
4 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
1 |
1 |
1 |
1 |
5 |
5 |
5 |
5 |
5 |
5 |
|
|
2 |
2 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1 |
1 |
|
|
|
3 |
3 |
3 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
|
|
|
|
|
4 |
4 |
4 |
4 |
4 |
4 |
3 |
4 |
|
f |
f |
f |
|
f |
|
f |
f |
|
f |
|
|
There are total 7 page faults with four frames in this case. Will adding more frames always improve the page fault? No. See next example.
Assume there are five frames now and we reference the strings as indicted before:
|
1 |
2 |
3 |
4 |
5 |
3 |
6 |
1 |
2 |
3 |
3 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
1 |
1 |
1 |
1 |
6 |
6 |
6 |
6 |
6 |
6 |
|
|
2 |
2 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1 |
1 |
|
|
|
3 |
3 |
3 |
3 |
3 |
3 |
2 |
2 |
2 |
2 |
|
|
|
|
4 |
4 |
4 |
4 |
4 |
4 |
3 |
3 |
3 |
|
|
|
|
|
5 |
5 |
5 |
5 |
5 |
5 |
5 |
5 |
|
f |
f |
f |
f |
f |
|
f |
f |
f |
f |
|
|
There are nine page faults which is more than the case with 4 frames. Even though the process has one more page frame, it also incurs more page faults/swaps. This is called Belady’s anomaly.
- Optimal (OPT)
Can we do better? In fact we can; there exists an optimal page replacement algorithm (OPT)! And it's nice and simple and elegant. Here it is:
Replace the page that won't be used for the longest time (that is, the page whose next use occurs furthest into the future).
Unfortunately, implementing this algorithm is impossible, since it requires knowledge of the future. Oh, well.
- Least Recently Used (LRU)
But with a simplifying assumption, we can do surprisingly well. Assume locality of reference: that is, something that was accessed recently is likely to be accessed again soon. Many computer programs exhibit locality of reference. If we assume locality of reference holds, then we can implement "OPT" by looking at the past instead of the future. The Least Recently Used (LRU) page replacement algorithm assumes that if a page has been referenced recently, it is likely to be referenced again soon. Here's what it does:
Replace the page that's been unused for the longest time (that is, the page whose last access occured furthest into the past).
We can use the page table's accessed (A) bit to calculate LRU. Whenever a page fault occurs, the system inspects the A bits of each page. Pages with their A bits increased have been recently referenced, whereas the page with A bits at zero have not. Here is the basic algorithm that implements this concept:
If
(page P isn’t accessed)
P.age++;
else
P.age=0;
clear all A bits
Most operating systems replace pages using a variant of LRU.
LRU looks backward in time, rather than forward; and locality of reference is not always true. Therefore, LRU can replace a page not knowing that page is about to be used. For example, this can happen in the presence of sequential file access. While a sequential file reader is reading a single page, locality of reference holds; but once it switches to the next page, the previous page will not be referenced ever again, even though it was referenced recently.
Many OSes let applications encourage the performance of page replacement by providing hints. For example, the madvise(addr, len, flag) system call advises the system about how to handle paging; this way the system can choose appropriate caching techniques. The advice is indicated in the flag parameter which can be:
# define MADV_NORMAL 0 /* No further special treatment. */
# define MADV_RANDOM 1 /* Expect random page references. */
# define MADV_SEQUENTIAL 2 /* Expect sequential page references. */
# define MADV_WILLNEED 3 /* Will need these pages. */
# define MADV_DONTNEED 4 /* Don't need these pages. */
NOTE : MADV_WILLNEED and MADV_DONTNEED are pre-fetching advice.
I/O Hardware View
There are different kinds of devices on which a computer operates. We can classify these devices in the following sub categories:
- storage
- human interface
- transmission devices
The following figure will describe how the devices are attached and how the software using these components can control the hardware.
![]()
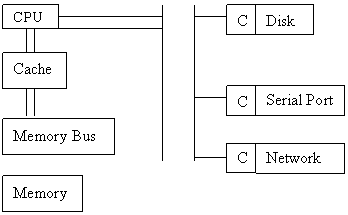
Each device communicates with computer by sending signal over the cable. If one or more devices sends the signal over the same wire that is called Bus. A Bus is basically wires that is shared between hardware devices. PCI Bus is a connector in between memory-CPU subsystem and other devices. Controller is a hardware interface with a bus which can operate a bus, a port or a device. Driver is software/operating system interface to the controller.
You might be wondering what the difference is between a controller and a MICRO-controller.
At a high level a controller can be thought of as something that is used to “control” some process or aspect of the environment. A microcontroller, on the other hand, is a highly integrated chip which includes on one chip, all or most of the parts needed for a controller. The microcontroller could be called a "one-chip solution". It typically includes:
- CPU (central processing unit) - RAM (Random Access Memory) - EPROM/PROM/ROM (Erasable Programmable Read Only Memory) - I/O (input/output) - serial and parallel - Timers - Interrupt controller
Typically microcontrollers are inexpensive since they are tailored for specific tasks and “power” is not important.
{source: www.faqs.org/faqs/microcontroller-faq/primer/}
Programmed I/O
How can the processor give commands and data to a controller to accomplish an I/O transfer?
The processor accomplishes this through reading and writing bit patterns from/in the controller. The controller has data registers and control signals for that purpose. Usually the following two function are used to perform this interaction:
byte = inb( port ) // TO READ IN A BYTE
outb( port, byte ) // TO WRITE A BYTE
Here is a typical interaction with the disk controller (refer to Lecture 2 for another example when we deal with bootstrapping):
outb( 0xCF7, z ) //set parameters
outb( 0xCF8, z )
outb( 0xCF7, 20 ) //tell controller to go and perform operation
while( disk not done ) //spin
inb(0xCF7)
//read
result
An I/O port typically consists of four registers, which are: status, control, data-in, data-out. The status register contains bits that can be read by the host. These bits indicate one of following three possibilities:
- Is Current command complete?
- Does any device error exist?
- Is there any byte available to read from data-in register?
The control register is written by the host to change the device mode or to start a command. Data-in register is read by the host to get input. Data-out register is written by the host to send output. . The special I/O instructions such inb() & outb() specify the transfer of a byte to an I/O port address. These instructions cause the bus to select the device and move the bits into or out of a device register.
I.
Polling
A complete interaction between controller and host can be taken place by a simple handshaking process. Let’s assume that we have 2 bits which coordinate the host controller relationship. The busy bit in the status register indicates the state of the controller. This bit is set when the controller is busy working and is clear when it can accept the next command. The host sets the command-ready bit when it is ready for the controller to execute. After this step the host writes the necessary output through a port by using following handshaking procedure and coordinating with the controller.
The hand shaking process is the following: First , the host performs a blocking read on the busy bit until it is ready, then the host writes a byte into the data-out register and sets the write bit in the command register and sets the command-ready bit (in the command register). When the controller detects the command-ready bit is set it will set the busy bit. In the next step, the controller reads the command register and notices the write command; then it reads the data-out register to get the byte. Following this, the controller clears the command-ready bit. Finally it clears the error bit in the status register to indicate “no error” and that the I/O succeeded. It also clears the busy bit to show that it is finished
II.
Interrupts
As opposed to polling, which used a “pulling” pattern, the interrupt driven I/O cycle basically follows a “pushing” paradigm—when the data is ready it is “pushed” to the process via an interrupt signal.
First, the device driver initiates the I/O by giving the controller proper input commands. Next when either an error occurs or input gets ready or output completes, an interrupt signal will be generated. While controller is trying to complete the appropriate tasks, the CPU checks for possible interrupts in between instructions. When the CPU receives the interrupt it transfers it to interrupt handler where data gets processed and the interrupt handler returns. Finally CPU resumes processing of interrupted task and the cycle continues.
III.
Costs
To allow for easier comparison between the various methods of data access let’s calculate the costs of each.
Let’s make the following assumptions about the parameters of our devices/machine:
1 GHz machine (1 cycle = 1 ns)
1 PIO instruction = 1 µs (1000 cycles)
1 interrupt = 5 µs (5000 cycles) NOTE: this includes saving state, jumping, and any other associated overhead.
and the timer is 100 Hz = 10 ms
When a process wants to read a sector from the disk, the following sequence of events take place under a polling system:
- Set command for controller using PIO instructions → (5 PIO)
- Sleep
- On every timer interrupt, check to see if the controller is ready.
If so, read result → (1 PIO)
We can now calculate the usual statistics (Latency and Throughput):
|
Latency: |
Throughput |
|
= ½ * (timer interrupt interval) = ½ * (10 ms) = 5 ms |
= 1/(total time for PIO’s) = 1/(6 µs) ≈ 105 requests per second |
In the next lecture we will explore the costs associated with the other methods.