CS 111Scribe Notes for 4/13/05by Jon Binney, Alexandra, Adriana Magana, Kathy LeeProcessesProcess Control BlockFor each process, the kernel maintains some state in memory. This state includes the ID of the process, the memory of the process, and a few other things. When a new process is created using fork(), it inherits most of its information. Below is listing of all of the parts of the control block for each process, and whether it's the same, different, or a copy of the process which it was created from.
Detail Note: The file descriptor table is copied, but
individual file descriptors are shared. This means, for example, that a
file opened in the child is not available in the parent. (Opening a new
file adds a new file descriptor to the file descriptor table, and file
descriptor tables are not shared between parent and child.) However, if
the parent opens a file System Calls
fork() creates a new process which is a copy of the parent process. But how will the new process know that it is the child, and not the parent? fork() solves this by returning a value of zero to the child process, and by returning the pid of the child to the parent. (a positive integer). If there is an error and the child process cannot be created, then a value of -1 is returned to the parent. Consider the following code for creating a new process using fork(). What will happen when the code is run? Carefully consider the order in which commands are executed! What will be printed by this segment of code? When the instruction pointer reaches the fork() command, an identical child process is created and run. It starts at the first command after the fork(), so the "printf("Pre-fork...\n")" command is run twice! Then the if statement on line 5 causes the parent to print out the child's pid, and the child to print out its own pid, and its parent's. Finally, if the return value of fork() is negative, the program aborts. Assuming a pid of 3 for the parent process, and 42 for the child process, would be: Pre-fork... P, C is 42 Pre-fork... C 42, P is 3 The order of the statements may vary each time the program is run, because the system is alternating between the two processes. In this case, the parent process was finished outputting before the child started. If the processes were scheduled differently, however, we could see the lines in a different order. Next let's modify the code so that "Pre-fork..." is printed only once, by putting line 4 before the fork(). Now the parent process prints out "Pre-fork...", then creates the child process using fork(). They each print out some info, and all is well. Or is it? What if the kernel decided to switch between processes halfway through one of the printf commands? Then the output might be interleaved, resulting in sompething like: Pre-fork... P, C is C 42, P is 3 42 Is this kind of problem possible? Lets look at a couple of possible implementations of the printf() function to find out. The most obvious way to implement printf() is to loop through the given string, calling write() on each character to write it to the screen. With this implementation of printf(), interleaving of output from multiple processes is a definite problem. There is nothing to prevent the kernel from switching to another process halfway through the string. In order to fix this problem, we need to note that system calls are atomic; meaning that the kernel will not switch to another process halfway through a system call. The solution, then, is to use just one system call instead of many of them in a loop. In this implementation of printf, we make just one call to write(), and tell it to print out the entire string. Since write() is a system call, we can be sure that it will finish before the kernel switches to another process. When you run the program, the output appears to be correct. Then you try redirecting the output into a file, and notice that the resulting file looks like: Pre-fork... P, C is 97 Pre-fork... C is 97, P is 45 Why is "Pre-fork..." printing out twice? The answer lies in the way printf is actually implemented by the operating system. When writing to the screen, printf works as we expect; when we call it with some string, it writes the string to the screen and exits. When it is writing to a file, however, printf() attempts to minimize the number of system calls. It stores all of the strings you tell it to write to file, and then periodically writes them all at once. This implementation looks something like (some of this is just pseudocode, but you should get the idea): When we call printf("Pre-fork...\n") in the parent before we fork, it might not actually get written to the file yet. Instead it is put into the buffer that printf() maintains. When we call fork(), the new process is a copy of the old process, including the memory, so it inherits the same buffer. Then when the child calls printf, whatever was in the buffer from before is printed out. To correct this, we must flush the buffer before forking. The corrected code is: Now, since we call fflush(stdout), the buffer is flushed and the problem is fixed.
In our final version for this subsection, let's communicate a bit of information from the child to the parent. Now the parent will not exit until the child completes, and that the parent prints the child's exit status. SignalsWell, one problem is fixed; but now the child counts up to a billion before exiting! The parent is going to wait for a long time on line 9. What if the parent decides that the child's computation is no longer important? We need some way for one process to interrupt another. That is, we need some form of asynchronous notification. In C and Unix, asynchronous notification is implemented
by signals. The operating system defines a set of signals, which
are given names like The operating system will automatically generate some signals; for
example, it generates a To define a signal handler, the process calls the int kill(pid_t process, int signal); typedef void (*sig_t)(int signal); // function pointer type sig_t signal(int signal, sig_t handler); Note that signal handlers have exactly one argument, the signal number. There's no way to pass more data with a signal. If you want more complex inter-procedure communication, you need to send real messages. Let's use the signal functions to do some asynchronous notification.
Our first goal: Make the child process's exit status equal the number
of Close, but no cigar. Remember that after the How do we get around this? The simplest way is to set up the signal handler before the fork. Signal handlers are copied between forked processes, so the child will have the right handler from the get go. But the parent must restore its signal handler. So:
As you can tell, signals are somewhat hard to deal with. But it gets
worse. Many function calls should not be used from within signal handlers,
including old standbys like Child’s Stack This shows a picture of the child process's stack after a signal is
delivered. The operating system has decided to deliver the signal on
top of the current stack. The uppermost stack
pointer 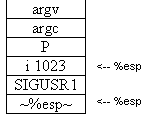 ThreadsWhat are threads? Threads are basic units of CPU utilization; they are multiple threads of control in a program that run concurrently in a shared memory space.
Processes vs Threads
Why are threads useful?
fork vs clone fork() is a system call that creates a new process as well as a copy of all associated data structures of the parent process -- that is, the VM is copied. Clone() is like fork except that instead of copying memory, the child shares the parent's address space. That is, instead of copying all data structures, the new process points to the data structures (such as the data structures representing the list of open files, the signal-handling information, and virtual memory) of the parent process. That is, a cloned process is effectively just a thread! A new process control block and a new process ID are created with the use of clone. Type man clone in the Linux shell to view API for this system call. The following code depicts the issues encountered when using clone to create threads:
int main(int argc, char *argv[]) {
pid_t p;
if ((p = clone()) > 0)
/* parent */
else if (p == 0)
/* child */
else
abort();
}
Problem with the above code: return value p is going to be the same in both parent and child because threads share the same memory space (p resides in the same address for both parent and child). Therefore, because threads share memory space, a new interface to create threads is needed. Pthreads is a POSIX standard API for thread creation and synchronization functions that manipulate threads from C programs. This API contains the function pthread_create (which uses clone) to create threads, and it's precisely the use of this function that fixes the problem in the previous piece of code. The difference lies in that pthread_create takes in an address where the child process id is to be stored in the stack allocated to the child process. So p is no longer overriden. Pthreads also contains the function pthread_join. Termination of a thread unblocks any other thread that’s waiting using pthread_join. pthread_create API: #include <pthread.h>
 Following is an example program that uses pthread_create. This example was not discussed in class but I found it to be helpful in understanding how pthread_create works.  This is what happens during execution: 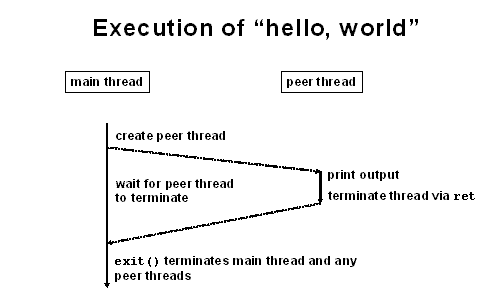 figures presented in the thread section can be found at: http://www.cis.upenn.edu/~lee/05cis505/slides_pdf/lec3-processes-v3.pdf SchedulingWhat is scheduling? When there are more than one process exist, scheduling refers to the task of managing CPU sharing among those processes. Whenever a process want to use the CPU, it make a request to scheduler, and if the CPU is available, the scheduler will allocate this process to CPU. Whenever the running process wait for I/O, scheduler will allocate another process who is waint to CPU. With the scheduling mechanism, the CPU utiliation is optimal. This mechanism overlapping computation to utilize resources efficiently. The CPU utilization is max and the throughput of total amount of work done is max as well. Since all processes share the CUP, the latency which is delay to completion will occur, and there is waiting time as well. The user latency which is delay for user actions is acknoledged. |
CS111 Operating Systems Principles, UCLA. Eddie Kohler. April 19, 2005.