This lecture will cover the remainder of Virtual Memory and the beginning of File Systems.
Performance
Lets consider our new memory mapping function, given by B(va, priv, write),
where va is the virtual address for which B will return a physical
address. Priv is the privilege level of the currently executing
code, which allows us to have user and kernel space in same memory space. Write
identifies whether the current access is a write, which is used to detect dirty
pages. The B function returns either the physical address that va maps to or
a page fault, in which the OS must decide what to do.
Lets look at how the OS might handle a page fault:
PF(va) {
If (va is swapped out to disk) {
Choose a page to replace;
Write to disk (if necessary);
Read this page in from disk;
Install mapping in B;
Return;
}
***
}
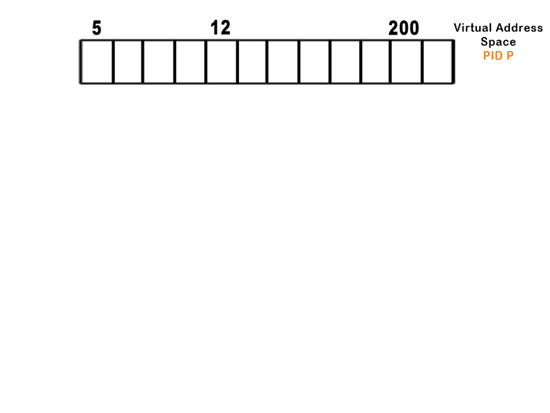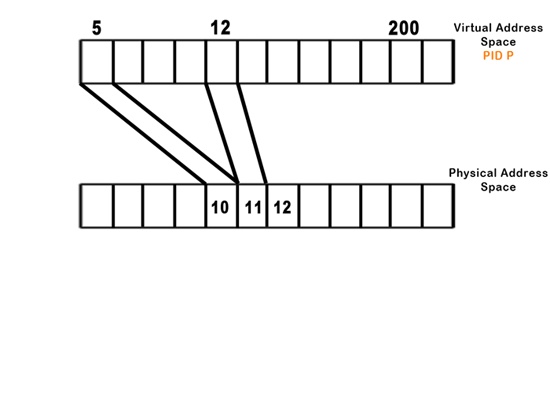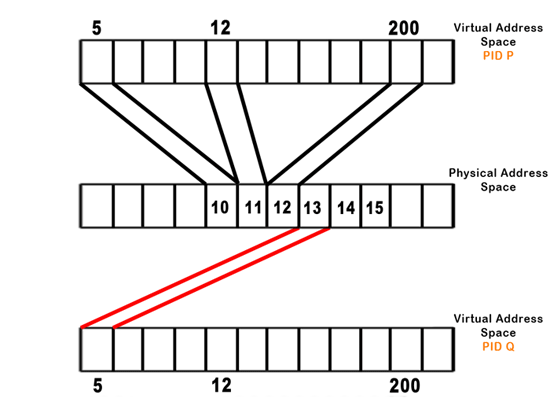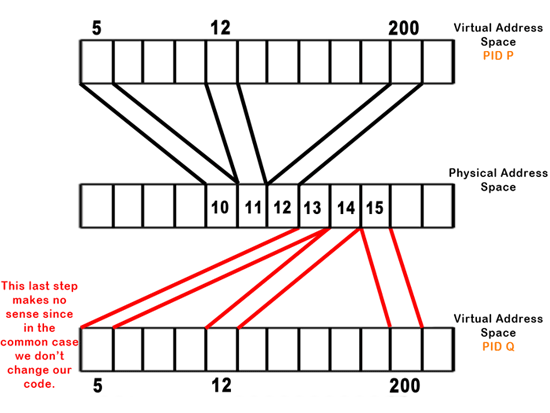
There are a few more things that go on at the *** in a real OS. Let's look at a fork using a feature called "copy-on-write" to get an idea. First, here is how fork would work without copy-on-write. Notice that the two processes each have a copy of the exact same data in both virtual and physical memory space:
The goal of copy-on-write is to copy a page of memory only when necessary. Ideally, this would mean to only copy when a change in one process could be observed by another. Practically, this means to copy when there's a write to the page of memory. So, how do we implement this functionality, in order to catch the write before it happens? The key idea is to make every page read-only by page faulting on every write. In order to do this, we must install it on the B function of both the parent and the child as such:
B'p(va, perm, READ) = Bp(va,perm,READ)
B'p(va, perm, W) = PF
So, this means adding the following else if statement to the ***
above:
Else if (write == W && va is marked copy-on-write) {
Allocate new page
Copy old data into new page
Change B(va)->new page; W OK
Return;
}
Now, our successfully implemented copy-on-write method behaves like so:
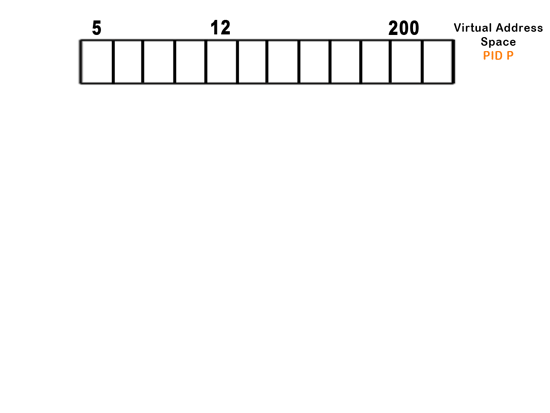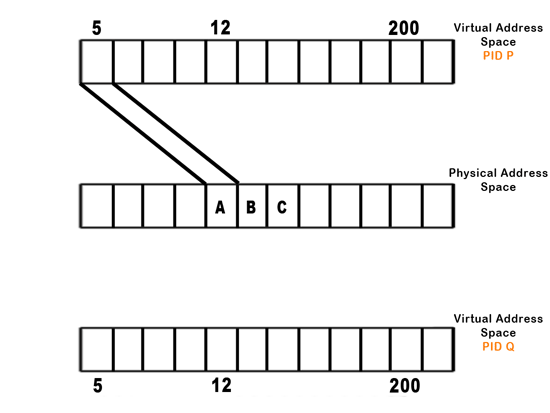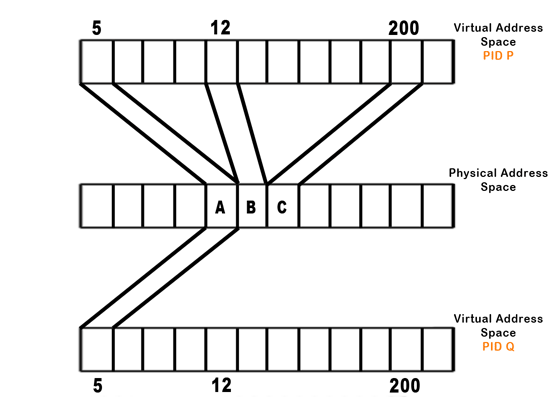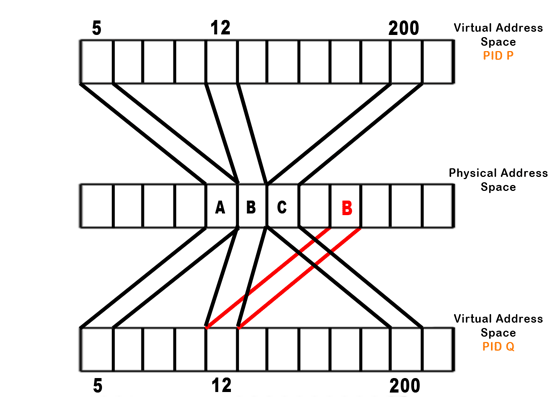
All this happens transparently, returns to the process, and continues without interruption. We need to write to a new page since the old page might be shared by another process. This also means that the processor must keep track of how many processes map to a particular physical address. This is clear in the condition when there is only one process currently with access to a physical address that was formerly accessed by several processes. The processor must know that there is only one process left, so that it doesn't copy-on-write for every memory access. Similarly, if a process is forked twice (so processes A, B, and C map to the same physical memory) and process A is killed, the OS must know that a write by process B to memory still necessitates a copy, so as not to affect C's data.
It is of note that the B mapping function is per-process. The OS designs a B for each process and installs it in the processor before running the process. Additionally, the OS needs its own bookkeeping for physical memory, in order to know if a page is allocated or free, or how many processes share a page.
To see how this affects performance, consider a process with N pages mapped. Suppose copying a page takes C cycles (C is approximately 5,000 - 10,000). After a fork, the process write W pages. A page fault costs F cycles (F is approximately 5,000). For an eager fork (in which all memory is copied on fork), time spent copying and latency are both equal to NC. Alternatively, for a copy-on-write fork, time spent copying is W(F+C), while latency is 0.
Demand paging
In order to emphasize the need for demand paging, let's talk about a big binary.
We want to reduce application startup latency when loading a new binary from
disk. The idea is to load pages into memory only when needed. So, we use a "shadow"
page map function for what the behavior should be:
/--> Load data from disk address Bshadow(va,perm,w) --> Allocate fresh page (demand loading for new stack, heap pages) \--> Segmentation fault (usually means that va is an unmapped address)Now, we continue to add to the *** of our page fault function:
Else if (Bshadow(va,perm,w) != seg. Fault) {
If (Bshadow loads from disk) {
Allocate page
Load data from disk
Install page into B
Return;
}
Else if (Bshadow == fresh page) {
Allocate page
Map into B
Return;
}
}
But, using only demand paging is slow. Every memory access results in a PF,
which makes loading very slow. What if we were to read more than one page at
a time (i.e. do the operations of the If (Bshadow loads from disk)
statement above 5 pages at a time)? This would decrease latency for pages 2-4,
but increase it for page 1 by a factor of 5, since it takes 5 times as long
to read data from disk). And thus we see the need for prefetching.
Prefetching
The central idea is to fetch data in the background that is likely to be needed
soon. For example, if a program counter is in page n, page n+1 would be a good
candidate for prefetching. Similarly, if a row of an array is accessed, we might
want to prefetch the next row. In order to implement this, we only block for
the read of the first page:
// Prefetch 5 additional pages if required
If (Bshadow loads va from disk) {
Allocate pages from va,...,va+5
Send read requests to disk for pgs va,...,va+5
Block until va is read
Install B(va)
Return;
}
When disk read request completes
If for prefetched page
Install mapping into B for the right process
Thus it makes sense to prefetch an entire binary if there is room in memory.
Otherwise, it is more expensive to constantly swap in the necessary memory than
it is to simply load on demand.
Complete PF function
We now have a (relatively) complete function to respond to page faults in the
B mapping. This includes copying-on-write, demand paging, and prefetching.
PF(va) {
If (va is swapped out to disk) {
Choose a page to replace;
Write to disk (if necessary);
Read this page in from disk;
Install mapping in B;
Return;
}
Else if (write == W && va is marked copy-on-write) {
Allocate new page
Copy old data into new page
Change B(va)->new page; W OK
Return;
}
Else if (Bshadow(va,perm,w) != seg. Fault) {
If (Bshadow loads va from disk) {
Allocate pages from va,...,va+5
Send read requests to disk for pgs va,...,va+5
Block until va is read
Install B(va)
Return;
}
When disk read request completes
If for prefetched page
Install mapping into B for the right process
Else if (Bshadow == fresh page) {
Allocate page
Map into B
Return;
}
}
}
Memory-mapped file
The idea is to make demand paging accessible to user-level applications for
files. Then we'd be able to change this typical code:
int fd = open(filename,...) char buf[]; read(fd,buf,size); // blocking for disk files
In UNIX, a memory-mapped file call would look like this:
addr = mmap(...,length,...,fd,offset);
This loads length byes of data from fd starting at
offset into memory and returns the address. Additionally, it marks
the address in Bshadow, thus only blocking on a PF.
One of the advantages of this technique is the reduction in copies, since the
disk driver can put data in the right memory location. Another advantage is
the addition of prefetching to file reads. But how do we know what to prefetch,
since file reads are not necessarily sequential?
We introduce the madvise(addr,length,behavior) function, where
addr and length define the region of some memory-mapped
file. Behavior causes the function call to advise a particular
behavior, either prefetch, which suggests sending read requests to
the disk, without blocking, for the defined region, or defetch, which
suggests that the process no longer needs this data and it is thus a good choice
to swap out of memory. It is important to note that madvise improves
performance, but does not necessarily change functionality. A PF on prefetch
or defetch still behaves under our normal PF function, so an advised functionality
can not cause an incorrect behavior.
B implementation
So, now that we know what the mapping function B does and how it is used, we
need to know how it is implemented. Though it varies from machine to machine,
the x86 uses a two-level page table. There is a register--CR3--that points to
the current page map. Given a virtual address, the two-level page table is used
to map and subsequently look up the corresponding physical address. The process
is simple but requires a few combinatorial steps, as seen below:

There is usually also a cache, commonly known as the Translation Lookaside
Buffer (TLB), for the page table that speeds up lookups.
Disk storage media
Disks are necessary in order to provide a persistence of data. They are additionally
a cheap means of storage. Their most common modern forms are magnetic storage
(hard drives) and optical storage (cd-roms).
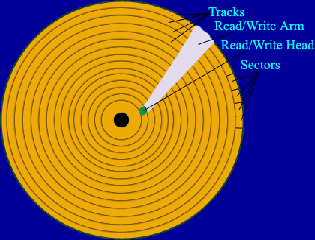
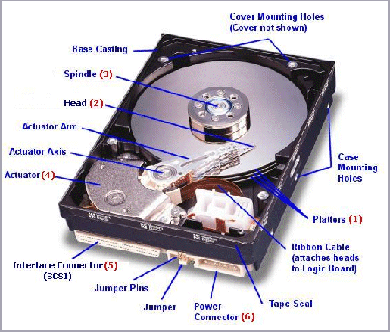
The hard drive is made up of a stack of magnetic platters that are read using a mechanically operated arm and magnetic head. Each dual-surfaced platter is made up of several thousand tracks made up of equally-sized sectors. The sector is the atomic unit of reading and writing on disk, commonly 512 bytes in size.
 |
|
Let's look at the physical specifications for a (formerly) typical hard drive on the market, the Seagate 73.4 GB SCSI. The Seagate has 12 platters (more than most of today's HDs), each with 14,100 tracks per surface (two surfaces per platter). It operates at 10,200 RPM with a peak transfer rate of 160-200 MB/s, or .014 ms/sector.
In order to move the read/write head from track to track, the arm must physically "seek." This is a time-expensive operation compared to the order of memory reads. The seek consists of acceleration (at about 40Gs), coasting, and slowing/locating, the whole of which takes on average 6ms, and to an adjacent track .6ms. An additional time cost is incurred when we have to wait for the desired data of a particular track to rotate and line up with the head. This is called rotational latency, and on average is 2.94ms for our example Seagate. With these times it is clear that SEEKS SUCK due to the slow physical motion; OS performance is often bottlenecked on these disk seek times.
We attempt to minimize seek times by arranging data on the disk to ensure that locality of reference corresponds to proximity on disk. This essentially means that references to data (that is, reads and writes) that occur close together in time, should be close together on disk. We will look at this in further detail in the next lecture.
Issues of file systems
There are several things to take into consideration when implementing file systems,
which resemble the OS considerations. Performance is absolutely necessary to
make a file system usable. In order to ensure this, we utilize smart caching
and a good layout of data on disk. Second, a file system is nothing without
robustness. This means the disk and its data must always recover from failures
such as power outages. Lastly, efficiency is a concern of maximing disk space
so that we can use as much of it as possible to store user data.
File systems generally represent the disk as an array of sectors. If we were to simply allocate files sequentially at any size interval, we would find a great deal of external fragmentation in the disk. So, we divide the disk into blocks (commonly 4KB), so that files can be a disjoint series of blocks, if necessary. Just like earlier we mapped virtual memory to physical memory, here we will map file names to a set of blocks.
We will continue with disk layout and file system semantics next lecture.