Authors: Steven Wei, Richard Strong, Micah Wendell
How can we build a file system that can survive failure? In the case of untimely power failure, we have discussed the advantages and disadvantages of journaling and ordered writes. However, what if the disk fails? In real life, hard disks can fail in at least a couple of ways. Either the entire disk can die, or individual disk sectors or blocks can become unusable due to too many writes being performed at the same location.
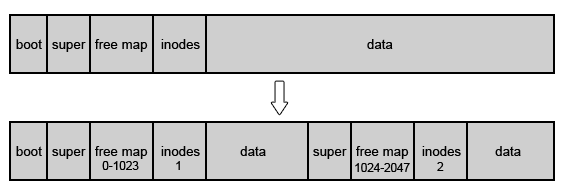
Problem: The superblock contains data about the entire file system. In a design with only one superblock per disk, we risk effectively losing the whole disk in the case that the superblock becomes corrupt. We can fix this problem by keeping multiple copies of the superblock throughout the disk. That way, if one fails, we can still use the other copies. This maintains robustness through redundancy.
Idea: Let’s try keeping five superblock copies in blocks 1, 2, 3, 4, and 5.
+ Advantage: Fewer seeks to keep all five up-to-date,
because the blocks are close together.
- Disadvantage: Failures will probably render all five useless, since they are all in the same location.
If a single platter, track, etc, fails, we will lose all of the superblocks.
For true redundancy, we need independent failures. Therefore, we should distribute superblock copies throughout the disk.
The free block bitmap and the inode array are also critical to disk operations. We must also distribute these structures across the disk for robustness, in order to avoid single points of failure. Here is a diagram illustrating how we can do this:
Distributing critical file system structures helps if only part of the disk fails, but what happens if the entire disk dies? For robustness’ sake, we can copy the entire disk. The methods in which we duplicate disk data are described as RAID levels.
RAID LEVEL 1: Mirroring
At this RAID level, we store the same data on two disks. Then, we read from one of the two disks until it fails. At this point, we can still access the data on the other disk. Here is a diagram and an algorithm to represent RAID mirroring:
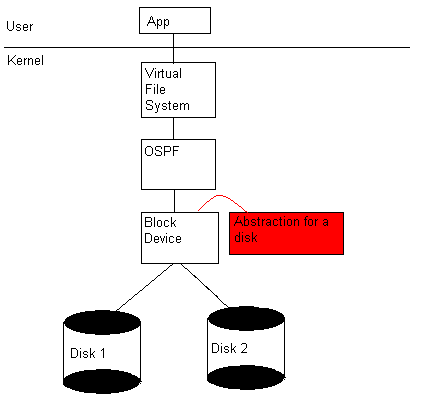
On write (block b): Write b to disk 1 Write b to disk 2 On read (block b): Read b from disk 1
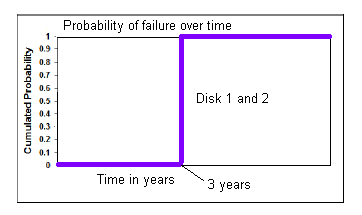
RAID provides no advantage in the following failure scenario due to the sharp change in probability of failure:
RAID provides an advantage in the following failure scenario because of the gradual increase in chances of failure of the disk:
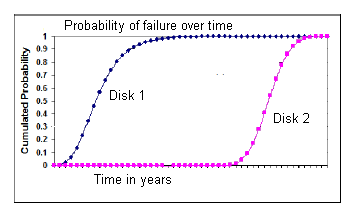
A device’s mean time to failure (MTTF) is defined as the mean (average) time until there is a 50% chance that the device has failed. We can evaluate the robustness of a RAID level, by examining the MTTF continuous distribution function (cdf) of the system as a whole. The closer a RAID level’s MTTF cdf is to the ideal (that is, the probability of failure versus time curve exhibits as small a slope as possible), the more advantageous it is to implement that form of RAID.
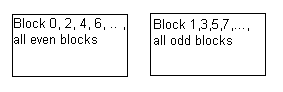
RAID Level 0 : Striping
In this RAID level, we keep all even numbered blocks on one disk and all the odd numbered blocks on another. Therefore, this RAID level provides twice the disk-access bandwidth of a single disk.
RAID Level 4: Block level parity
Here, we use several disks to store data and an additional disk to hold parity bits. For every block, we perform an XOR operation across the data disks and store the results on the parity disk. Then, if any single disk crashes we can calculate the data that was on that disk by XORing across the remaining disks.
Disadvantage: every write operation requires an update to the parity disk. Asymmetric usage results in quicker failure of the parity disk.
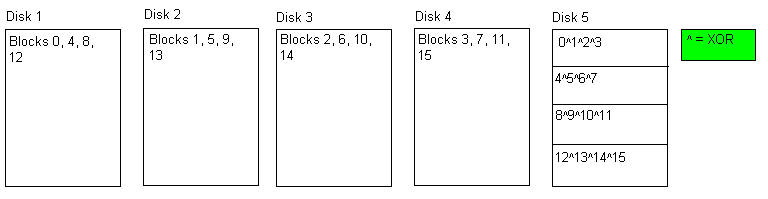
Example: What if disk 2 crashed? We would XOR(1,3,4,Parity) to calculate the missing data. Since Parity = (0^1^2^3)
0^1^3^(0^1^2^3) = (0^0)^(1^1)^(3^3)^2 = 2
RAID Level 5 : Distributed Block- Level Parity
This RAID level addresses the asymmetric usage of the parity disk in RAID level 4. In this level, we split the parity bits over all of the disks. Therefore, every disk contains both data and parity bits, resulting in symmetric usage of all disks.

Distributed Computing
Distributed System (n): A system in which the failure of a computer you didn’t even know existed can render your computer unusable. (Leslie Lanport)
Networking in Systems
One of the main differences with networking is that is is more unpredictable than working with a local machine. Our computer is not in control of the network. In fact, attackers may be in control of the network, which implies that defensive actions must be taken.
Goal
Distributed systems coupling:
|
Closely Coupled |
Loosely Coupled |
|
Failure together |
Failure independent |
|
If any component fails, the systems fails. (Like a business system) |
If a component fails, the system still works (Big Advantage) |
The internet (web, email, ftp, Bittorrent, etc) is a loosely coupled system.
The basic idea of DSM is that we can swap to other computers instead of our disk! Paged virtual memory provides the illusion of a larger memory by swapping pages to and from disk. If other computers are available, we can provide the illusion of having one huge memory by swapping pages between computers, instead of just to the disk.
We must modify our page fault algorithm in order to handle DSM:
PF(addr) If ( copy_on_write fault ) Allocate page Copy data Remap Return If ( address is on DSM page ) Look up computer C that owns page Send C message asking for page. Wait for response Write response into memory Map page Return
This is useful in scientific computing applications such as climate modeling, which consists of mainly local interactions. This type of application also makes it easier to manage shared memory.
Problems:
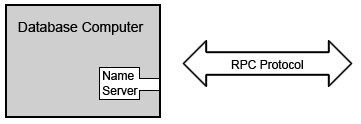
An RPC allows software running on disparate operating systems, running in different environments to make procedure calls over a network. The functions hide the details of the RPC from the rest of the computers on the surrounding network. Each RPC call requires parameters and returns a value. The advantage of this system is that it moves computation to another computer, freeing resources on the current computer for other processes. The major disadvantage to RPC is that it may block forever depending on the state of the network, requiring some procedure to detect such a scenario. Two likely solutions are retransmissions and timeouts.
The advantage of RPC is that it looks like a regular function call and has automatic stub generators. The disadvantages are that the function can fail, timeouts delay execution, malformed replies and requests from/to the remote computer are possible, the RPC function has a greater chance of failure than normal procedure calls, and last, the detection of failure of a RPC takes longer due to the blocking condition. A noteworthy difference is that pointers may not be used in RPC. Different address spaces indicate that pointers have no context across machines. The solution to this scenario is to marshal (convert a data structure into something transmittable over a network) data structures. Last, the global state data must be explicitly sent over the network as parameters, because the remote computer does not have this state information.
Example: This is how an RPC could be implemented
int f() { … printf() … unit32_t value_lookup(“name”); } unit32_lookup ( const char * name) { char message[...]; construct message (marshalling) copy name to message; send wait for reply (careful... this could block forever) parse result - interpret bytes as integer (unmarshalling) return result; }
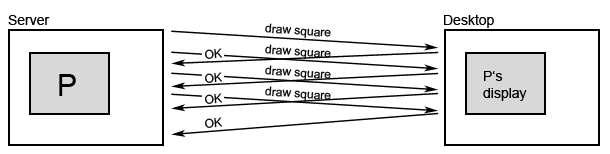
Asynchronous RPC: an alternative to synchronous RPC is asynchronous RPC. The RPC no longer blocks when called on the client machine. This systems has many parallels to non-blocking I/O in the sense that the function may return 'not finished'. This improves several of the disadvantages associated with timeout and retransmission.
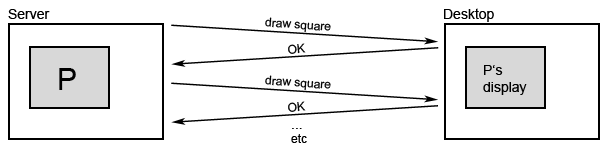
Example from class: Remote Display desktop
Asynchronous RPC makes the user experience more smooth, by sending all draw() requests at once, so it could track the mouse position more often.
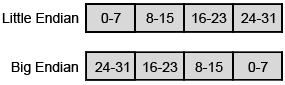
Byte order is an issue when communicating with a remote computer. General computer architectures vary in their use of the little endian and big endian byte order structures. The internet however uses the big endian format, which requires many messages sent by little endian machines to be converted to network order (big endian) in order to pass information successfully over the network.