Lecture Notes for May 9, 2005
By David Law, Dennis Nguyen, Young Wook Choi
Midterm
Problem 1: Therac/Flash Question
It appears that many people did not understand the meaning of “software architecture”. It can be defined as the global structure of software: the highest-level decisions made by the software architect. For example, is the software one process, or many? Does it precompute data on disk, or calculate the answer from scratch?
When deciding which architecture best resembles the Therac-25 software, we consider how many processes are running, (i.e. how many concurrent tasks are running) It is clear that MP and AMPED implement multiple address spaces, and thus those choices can be eliminated. Like MT, the Therac-25 software also features preemptively-scheduled "threads"; whereas in SPED, tasks are cooperatively scheduled.
Problem 10: Once the hang problem is fixed, you notice that Glasspanes slows down significantly when there are more than about 30 processes. Different processes, which call pcb_lookup with different pid_t arguments, spend a lot of time waiting on the process_table_lock. What is likely going wrong?
The problem here is not that you must traverse the linked list to find the element. This does not cause a big slow down since there are only 30 processes. Another problem that people mentioned was that it implemented a very bad hash function. This answer is better, but still not good: traversing a linked list with 30 elements is still super cheap! A far more likely cause for the slowdown is due to the fact that the processes are spinning and thus wasting resources with no work being done. Here are some types of locks people suggested, and what they did:
1. Spinlock (sleep/wake lock)
- Still only one process can access data structure at once.
2. Read/Write Lock
- Allows indefinite number of readers and one writer.
3. Fine Grained Locking
- Can have one lock per bucket, thus can have 31 concurrent accesses.
Memory allocation
Dynamic memory allocation involves 2 central commands: malloc allocates a portion of unused memory for use by a process, while free frees a previously-allocated portion of memory, allowing it to be reused. The operating system must allocate memory among all running processes, but processes themselves must also allocate memory at a finer granularity. Many of the issues are the same in each case.
So how can we implement these commands efficiently? First, let's consider an extremely simple algorithm: fixed size allocation.
Fixed Sized Allocation
Assume N = 32 bytes: everything allocated is exactly 32 bytes long.
If we are given a 32 MB Heap like this:

Fig. 1: 32MB Heap
|
1 |
0 |
0 |
1 |
… |
0 |
0 |
0 |
Fig 2: 1MB Free bitmap
This 32 MB Heap is divided into 32 byte chunks. In order to determine which chunks are free we need to do a little bookkeeping. Since there 1 MB of chunks, you will need 1 MB free bitmap to do the bookkeeping. Each byte would represent a chunk in the heap. If that byte is 1, then the chunk is being used, if the byte is 0, then the corresponding chunk is free for use.
With this bitmap, the algorithm for allocating a chunk would be:
Allocate
Search through bitmap
Look for free location
Turn bit to 1
Return Chunk
Keep in mind this whole sequence should be synchronized. There lies the problem of two processes attempting to allocate the same chunk at the same time. This would cause a very dangerous race condition.
To free a memory location the algorithm would be:
Free(chunk #i)
bitmap[i/8] &= (1 << (i % 8));
Also note that without synchronization, if two threads free two chunks in the same byte at the same time, one chunk might not look free.
There are both positives and negatives to this design. The positive is that it uses a single local data structure. However, this positive is more useful for disks than memory. Memory is much faster than disk in regards to changing to different chunks. The negative is much more glaring in this design. It is an O(n) algorithm for allocation! This is far too inefficient to work as memory allocation. As a result, we should look for other solutions.
One proposed solution would be to use 2 pointers: one pointer at the end of the heap and one free pointer that points to the most recently freed chunk. It would look like this:
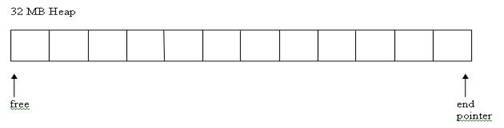
Fig 3: Free and End pointer implementation
The allocation of memory would go like this:
Allocate
If free < end
Return free++;
This would have an allocation algorithm of O(1). However there is a serious problem with this design: How would we ever free a chunk that was not the most recently allocated??
So what's a better solution? Make a free list: a linked list of free chunks. The head of the free list points to the first free chunk, and each free chunk points to the next free chunk. The design would be:
Allocate
If(free != NULL)
chunk = free
free = free-> next;
return chunk
Free
p->next = free
free = p
This uses the concept of using free space to maintain
bookkeeping state. The more free
space we have, the more free pointers we need. Conversely, the less free space we
have, the less of a need for free pointers. As a result, this design also results
in optimal use of space. We can
allocate all but one of the chunks (namely, the chunk containing the
free pointer itself).
And, since all allocations return exactly one chunk, and chunks are
100% independent of one another, the heap is nearly 100% utilizable. But a
malloc() that only works for N=32 is not much of a malloc at all! What
happens when we do not have fixed sized allocation?
Let us look at cases when N is an arbitrary number and the heap is still 32 MB. This is called Variable Size Allocation.
Variable Size Allocation
In variable size allocation, unlike fixed-size allocation, we need to
keep track of some bookkeeping information for allocated chunks as
well as for free chunks.
In particular, the free function must know the size of the
chunk it's freeing!
One common way to do this is to store bookkeeping information
immediately before the pointer returned by malloc.
For example:
typedef struct malloc_chunk {
int sentinel;
struct malloc_bookkeeping *prev;
struct malloc_bookkeeping *next;
char actual_data[]; /* pointer returned from malloc() points here */
} malloc_chunk_t;
Then, free can just use simple pointer arithmetic to find
the bookkeeping information.
A simple heap using this bookkeeping structure might look like this.
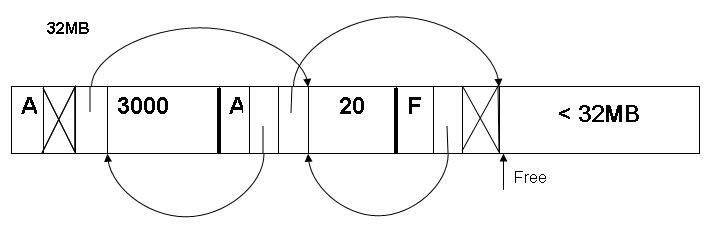
Fig 4: Implementation of variable sized allocation.
The first component of each chunk is called the "sentinel". It shows whether the chunk is allocated (A) or not (F). The second component has a pointer to the previous chunk, and the third has a pointer to the next chunk. (Notice that those pointers point at the chunk data, not at the initial sentinel!) An "X" the second or third column indicates that there is no previous/next chunk. The fourth component is the chunk data; we write the size of the data there. The first three columns are 4 bytes and the fourth column is the size of allocation.
The list of chunks is kept in sorted order by address; the size of any
chunk can be calculated through pointer arithmetic using the
next field. As before, free chunks are additionally kept on
their own free list, using the data areas; we don't show this list in the
diagrams.
What happens when alloc(3000) is called to an empty heap?
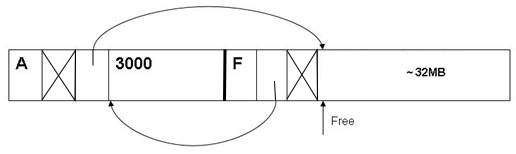
Fig 5: The heap after a call to alloc(3000).
What happens when we call alloc(1MB)? We will just look at the latter half of the heap from now on.
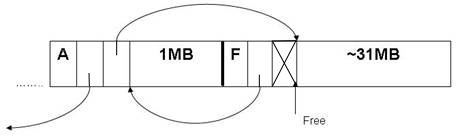
Fig 6: The heap after a call to alloc(1MB).
What happens when we call alloc(10MB)?
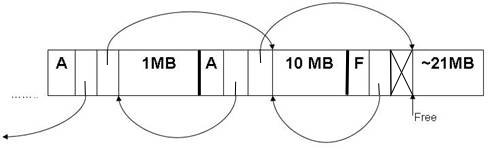
Fig 7: The heap after a call to alloc(10MB).
What happens when we call free(the 1MB chunk)?
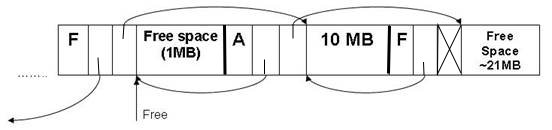
Fig 8: The heap after a call to free(the 1MB chunk).
Now, what happens when we call alloc(22MB)?
The call will fail. Although 22MB are available, the free space is split into two chunks, a 21MB chunk and a 1MB chunk. The chunks are noncontiguous and there's no way to move them together. The heap is fragmented, since it is unable to allocate 22MB even if it has 22MB of space. This type of fragmentation is called external fragmentation.
(There can also be internal fragmentation if malloc() returns chunks that are bigger than the user requested. For example, malloc(3) might commonly return a chunk with 8 bytes of data area, rather than 3; the 5 remaining bytes are lost to internal fragmentation.)
Free space is divided into noncontiguous chunks. Allocation can fail even though there is enough free space.
How can we solve external fragmentation? We could use compaction to solve this problem.
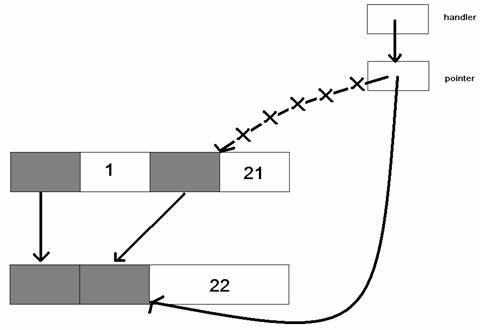
Fig 9: Compaction to solve external fragmentation
The heap is copied, but the free space is compacted to the right side. This allows calls like alloc(22MB) now! But compaction is extremely expensive. It requires copying a ton of data, and it also requires help from the programming language so that pointer variables can be updated correctly. Compaction is not used on OSes for modern architectures.
Compared to memory allocation with constraints N = 32 bytes, variable size allocation has more overheads, can run into external fragmentation, and internal fragmentation. To avoid these issues, we turn to memory allocation with paging. This lets the operating system use fixed-size allocation, with all its benefits, to provide applications with variable-size allocation!
Memory Allocation with PAGING
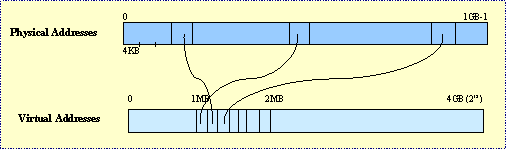
Fig 10: Virtual Address Space Implementation
Virtual Address Spaces:
- Reduces fragmentation by separating contiguous virtual pages from contiguity in physical address space.
- Provides for isolation between processes. Each process has its own space.
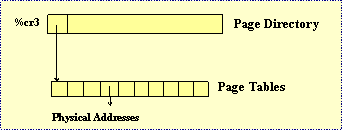
Fig 11: Paging
Paging allows the OS to avoid external fragmentation. Variable sized allocation built from fixed size allocation + hardware supported address indirection.
Page Faults occur when you try to access an invalid address. This can happen on execute, read, and write commands. The CPU traps on invalid accesses. In the x86, the OS gets a problematic address in the %cr2 register.
Memory Mapped files
When attempting a sequential read on a file on disk, we need to use system calls such as open(), read(), and write(). This can be quite costly if the file is rather large. Also, sharing becomes quite the pain. One alternative is memory mapped files. Memory mapping is when a process marks a portion of its memory as corresponding to some file. For example, suppose you wanted to read and write to /tmp/foo. This can be accomplished by memory mapping:
/tmp/foo -> memory address 0x10000
So when someone accesses memory address 0x10000, they are now accessing the start of the file foo. Because of this, the function that invokes memory mapping I/O would need to return a pointer to the start of the file. This function is called:
void *mmap(void *addr, size_t len, int prot, int flags, int fildes, off_t off);
The mmap function will return a pointer to the starting address, also known as the start of the file. In the *addr parameter, it allows the user to determine what address it would like to begin at. It is often best to place NULL and allow the operating system to decide. If the user were to place an address that the operating system does not like, an error will occur. The len parameter is merely the length in which the user wants to map the file. The prot parameter involves protection mechanism the user would like to enforce. The user can add such flags as PROT_READ, PROT_WRITE, and PROT_EXEC as permissions for the new memory mapped file. The parameter flags are any miscellaneous flags that the user wishes to set. For example, to allow sharing, the user can set the MAP_SHARED flag. The parameter fildes is the file descriptor that the opened file is on. Finally, the off parameter is the offset in the file that you want to start mapping from. An example of an invocation of this function would be:
addr = mmap(NULL, length, PROT_READ, 0, fd, offset);
Suppose that the we invoke the mmap function with a length of 1 MB and file descriptor 2. It would cause the following effect:
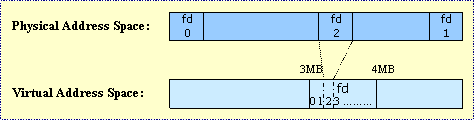
Fig 12: Fault on 0x308002, loads from physical address space.
What occurs now is that the files are read in the background into physical memory space. When the process faults:
OS checks if the addr is in mmapped space
If it is, then it will load that page of data from disk (unless already cached)
Add virtual memory mapping for that page
Some advantages/positives to memory mapping include no need for copying when not needed, and the ability to share a file amongst processes. If processes read the same file, they can share the same physical address. However, there are also some disadvantages to memory mapped I/O. A simple problem is that data must be page-aligned; user programs must be careful to ensure this. A more complex problem is the need to synchronize writes with the disk. Once a file is memory mapped, will the OS have to write out the entire file back to disk, even if only one byte was written? Another complex problem is unwanted sharing. Say a process P1 is reading a file, and another process P2 is writing to the same file. Before memory-mapped I/O, P1 could get a stable version of the file by reading its data into memory; no one could change P1's memory copy of the file data. But with memory-mapped I/O, it's possible that P1 would see all of P2's changes to the file, as P2 made those changes!
Hardware support
After talks between software and hardware manufacturers, the hardware manufacturers were able to improve the hardware to help support memory management. The result was a Page Table Entry like the following below:
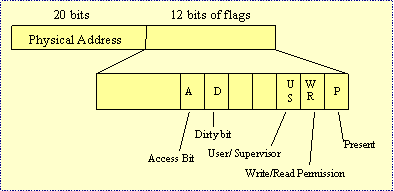
Fig 13: Page Entry Table
The new accessed bit and dirty bit are set by the hardware. The CPU sets the access bit to 1 when a portion of memory has been read or written, and sets the dirty bit to 1 when the portion of memory has been written to. The hardware never clears these bits; the operating system is expected to clear them as necessary.
This allows for more efficient writes to mmapped files. The operating system only needs to write pages of mmapped files when they have the dirty bit set to 1. All other pages have not been altered and consequently do not need to be written back to disk. This reduces bus traffic as well as overhead. Once a read has occurred, the file is changed and the OS clears the dirty bits on the pages of the mmapped file.
Writing to memory mapped file:
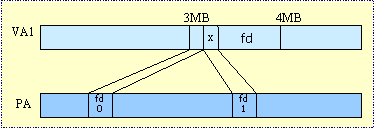
Fig 14: Writing to a mmapped file.
Trick: When synchronizing files with the disk, the operating system clears the dirty bit on all pages of the memory mapped file when they are first read in.
Note: Only write pages with D = 1! (Dirty bit set to 1). This reduces disk traffic for writes.
Copy-on-Write
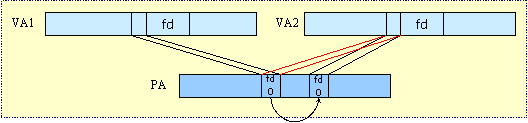
Fig 15: Copy-on-Write
To fix unwanted sharing, a copy-on-write algorithm can be applied. This algorithm allows sharing of pages between two processes until one process decides to write to it. When one process tries to write on a page, the page is copied so that each process has its own version of the page, as depicted above.
To copy-on-write, the operating system marks the pages in bookkeeping structure as copy-on-write and the virtual address mapping is set to NON-WRITABLE. When a process tries to write to the page, it faults!
When the operating system catches a fault, it copies the page, and changes the virtual address mapping to the new copied page. It sets the virtual address mapping to WRITABLE.
After this event, each process has its own copy of the page and is able to write to its own copies.
This concludes the lecture for May 9, 2005.