CS 111
Scribe
Notes for
by Amer Marji, Navin Kumar Jain, Alexandra Minevich, and David Dawei Shen
*Factoid of the day: Disk arm acceleration = 40g*
“Quote of the day: Any problem in computer science can be solved with another layer of indirection.”
File System Implementation
Evaluating FS
(Note: “+” means good; “-” means poor; “+/-” means mediocre or is just a statement)
We'll evaluate different file system designs with respect to three characteristics.
- Performance depends on the speed of reading or writing files. Good performance is being able to read or write a file at a good speed. Good performance can be achieved through minimizing seeks, using techniques such as caching in memory and making locality of reference correspond to proximity on disk.
- Robustness is basically availability. In other words, a system is robust if when crash, data is still on disk. Robustness can be achieved through replication (if there is more than one copy than there is better chance that one copy will survive) and simplicity: a simpler implementation is more likely to be correct, and to survive crashes.
- Efficiency measures the amount of space wasted on disk. A perfectly efficient file system uses 100% of the disk to store file system data; perfect efficiency is impossible. Efficiency is achieved through minimizing overhead: having small bookkeeping structures (inodes, directories, free block bitmaps, and so forth).
Allocation Policies
Let's investigate a couple different ways to store files (of arbitrary length) on a disk. How do we decide which sectors are used to store the file data? (The atomic unit of disk reading & writing is the 512-byte sector.)
First, let's store files in contiguous sector ranges.
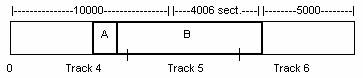
For example, to allocate a file of n bytes, we need to find ceil(n/512) contiguous free sectors, and then put the file there. What consequences does this have on performance, robustness and efficiency?
Performance: + There is minimal number of seeks/file.
+/− We haven't discussed inter-file locality. Since files are often accessed in groups, it can be important to structure the disk to put groups of files closer together.
Efficiency: − This is an external fragmentation issue. Maximum waste on the disk is 100%.
How can we avoid this fragmentation issue? Let's use the same technique we used in virtual memory: introduce a layer of indirection. We'll divide files into fixed-size blocks, so file data doesn't have to be allocated contiguously.
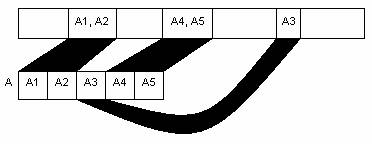
Performance: − Can suffer from a large number of seeks, at most one per block.
Performance characteristics depend on the block size.
Small Size Blocks (512 bytes) (The original Unix Fast File System [FFS] used 512-byte blocks.)
Performance: − There are more seeks and less contiguous allocations.
Efficiency: + The average fragmentation
waste/file is only 256 bytes (assuming random file lengths).
− Bookkeeping,
such as the indirection structure that maps file offsets to blocks,
introduces additional overhead.
Example: Real numbers from a 1 GB Unix file system (1980s): Without book-keeping, there was 4.2% waste; with bookkeeping, 6.9% waste.
Large Size Blocks (4KB, 8KB) Current Unix file systems use larger blocks.
Performance: + 8 times as much guaranteed-contiguous data, so 8 times fewer worst-case seeks.
Efficiency: − The waste/file is half the block size, or 2-4 KB on average.
Example: Same file system: With 4KB blocks and including bookkeeping, 45.6% waste on the disk.
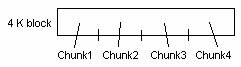
The performance advantage of large blocks is huge; modern FSes use large blocks. To avoid the expensive loss of efficiency caused by internal fragmentation, they use tricks. Unix FFS splits blocks into chunks, called "fragments" (4KB block into 4 chunks). The last partial block in a file can use 1-3 chunks instead of a full block. Small files (those that are less than 1 block) end up sharing blocks with one another, reducing waste.
Example: Same file system: With 4KB blocks and including bookkeeping, "fragments" reduce waste from 45.6% to 5%.
Boot Strapping the File System
Every file system has a certain variant of a super block that contains essential information about the disk organization and data structures. Having a single super block in a file system reduces the robustness of the system. If the super block fails, all the data on the disk is lost since it can not be located. File Systems’ designers tend to replicate the super block in different positions on the disk in order to increase robustness of the system.
![]()
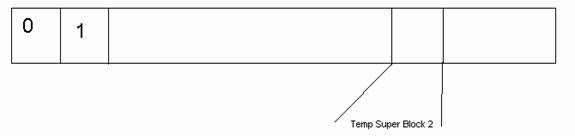
Super Block: 1- File System Type (magic number)
2- # of blocks
3- Root Directory
# Chunks/blocks
Boot Strapping/ Locating a File
There are many implementations and designs where different file systems use different ways and techniques in order to locate files on the disk. Directories point to files and subdirectories. The super block points to the root directory. Since a file can be bigger than one block, there should be a way to link these blocks together and locate the remaining data of each file. One method of design is to use intrinsic links. That means that the links are stored in the same place as the data. Here, the first 4 or 8 bytes of each block contain the block number of the next block in the file.
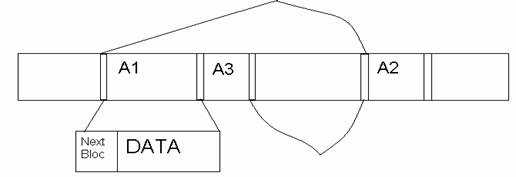
Intrinsic Links
If a block's link is −1, that means the block was the last block in the file. If a block's link is 0, the block is free.
Performance: − Say you want to seek to the 10th block in the file. There is no way to do this without reading the first 9 blocks! (You have to read the 9th block to get the 10th block's number, and you have to read the 8th block to get the 9th block's number, and so on.) Thus, seeking forward n bytes takes O(n) time (and O(n) expensive mechanical seeks).
Robustness: +/− This design is not very robust since losing one block of data leads to the loss of the rest of the file since the pointers are lost.
Efficiency: + It requires very little overhead, approximately 4 Bytes per block for the next-block pointer.
Another method used in file systems is to use extrinsic links to data. "Extrinsic" means we store the pointers in a different place than the data. This requires the system to keep track of all the links in the system. This can be done by keeping a link table at a known place on the disk.
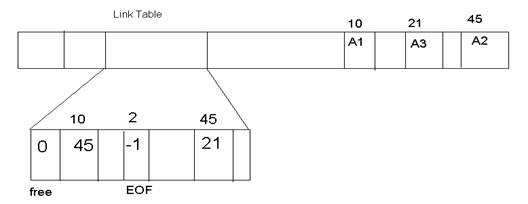
Thus, block b's link value is stored in link_table[b], rather than at the beginning of block b. Just like intrinsic links, a value of −1 means that block is the last block in the file. A vale of 0 means the block is free.
Performance: + Seeks to later file positions can be much faster if we cache the link table.
− Seeking to a file position is still an O(n) operation: we still have to traverse a singly linked list.
Robustness: − If one block in the link table is corrupted, we lose many files.
Efficiency: + No difference than the previous implementation.
*This design is used in the MS-DOS FAT (File Allocation Table) file system.
Indexed Block Pointers
How can we get rid of the O(n) cost of seeking to a particular file position? Well, instead of storing a singly linked list of block pointers, store an array of block pointers. To seek to file f's 3rd block, access f_block_table[2].
In this file system, a directory contains an array of block pointers (whereas in FAT, a directory points to the first block). To be specific it only has 10 block pointers. So if a file needs more than 10 blocks what do we do? Here come the indirect block pointers that points to a block that contains 1024 block pointers. So what if the file is even larger, then in this case we will use the Indirect 2, which in turn points to a block of indirect pointers. For a block of size 4 K, an indirect block will have 1 K pointers. A file with direct pointers has a maximum size of 40 K. A file with indirect pointers has a maximum size of 4 MB. A file with indirect2 has a maximum file size of 4 GB.
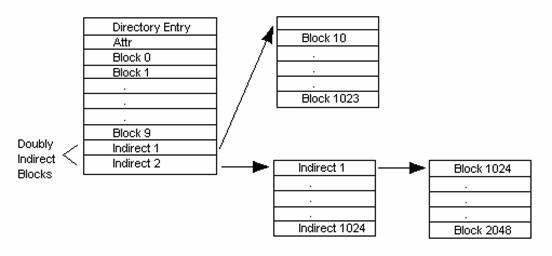
Performance: + Indexed so we do not have to traverse the links: seeking to a file offset is O(1).
− Harder to cache links.
Robustness: + Block damage is localized to directories.
Efficiency: − There are more pointers/file.
− We still need some global structure to store information about blocks are free. Best we can do is a Free Block Bitmap (1 bit/block).
*This design is used in the UNIX FFS (Fast File System).
WRITE ORDERING
In what order should writes (and reads) be performed?
FCFS (First Come First Serve)
Performance: − Ordering will not be localized, thus resulting in many seeks.
Robustness: + In this case the disk is unlikely to get into an inconsistent state, so the operation is pretty robust.
Delay Write:
Performance: + The mechanisms employ a minimal number of seeks.
Robustness: − As the name suggests, the writes are written to disk at a later time, which may lead to inconsistent disk states.
Rules for UNIX
A write happens to disk at most 30 seconds after it was initiated or fsync() synchronizes the disk.
File System Invariants
1.) All blocks pointed to by files or directories reachable from the root are NOT free.
2.) All blocks NOT pointed to by files and directories ARE free.
3.) No block is pointed to by more than ONE file.
Let us consider an example of a file system that does not follow the above invariants. Say we are writing to a file A:
Allocate block 35
STEP 1: Marking the block non-free.
STEP 2: Writing 35 into the file's directory entry.
Now say that the SYSTEM CRASHES and only STEP 2 made it, but not STEP 1. We then proceeded on with the file system to write another file.
Now say we write to file B:
Allocate Block 35 (Thus we broke the first invariant, as well as the third since block 35 is now pointed to by multiple files).
We use fsck() to fix the above problem, but it takes a very long time to run. The operation walks the entire file system to check for all invariant validity. It is an invariant enforcer but causes performance issues in a file system. So we should try to avoid the use of fsck() by ensuring CONSISTENCY.
Soft Update
Soft update enforces invariants independent of write ordering that implies consistency. It avoids the older way of ordering the writes, which led to bad performance as it forces the disk to be used in a non-optimal manner.
CS111 Operating Systems Principles, UCLA. Eddie Kohler. May 18, 2005.