

In Wednesday 4/6's class, we built several tiny operating systems as "thought experiments". The first operating system did nothing but print "111" on the console; we used it to learn about hardware interaction and bootstrapping. The second operating system was a simple password checker. One program printed the password "111" to the second program, which checked the password. We used that OS to learn a bit about processes and process interaction, and to motivate the need for protection.
Well, these teensy-weensy operating systems aren't just thought experiments. They are real.
weensyos1.tar.gz |
Source code for WeensyOS 1.0, which builds these two hard disk images: |
print111os.img.gz |
Print111OS, which prints "111!" to the console. (This is actually a compressed image; you will need to expand it with the gunzip command.) |
passwdos.img.gz |
PasswdOS, which has two cooperative processes: the first writes a password to the second, which checks that password. |
In this simple problem set, you'll browse, partially understand, and change these tiny operating systems.
Please check back over the next couple days as we improve this problem set description.
You will electronically hand in code and a small writeup
containing answers to the numbered exercises.
The problem set code, weensyos1.tar.gz, unpacks into a
directory called weensyos1. (We explain how to unpack it
below.)
You'll modify the code in this directory, and add a text file with your
answers to the numbered exercises.
When you're done, run the command gmake tarball.
This should create a file named
weensyos1-yourusername.tar.gz.
Email this file as an attachment to kohler@cs.ucla.edu.
I won't be able to confirm that I got your problem set, especially if you
hand in at the last minute; so you may want to save a copy in your SEASnet
home directory.
Answers to the numbered exercises should be in a file named
answers.txt, answers.html, or
answers.pdf.
Text files are strongly preferred.
No Microsoft Word documents (or other binary format, except for PDF)
will be accepted!
For coding exercises (Exercises 2, 3, 5, and 6), it's OK for
answers.txt to just refer to your code (as long as you comment
your code).
To review:
weensyos1.tar.gz.weensyos1 directory.answers.txt file (or answers.html or answers.pdf) in that weensyos1 directory.gmake tarball from the weensyos1 directory. This will create a file named weensyos1-yourusername.tar.gz.weensyos1-yourusername.tar.gz file as an
attachment to kohler@cs.ucla.edu.You could take a disk image file like print111os.img, write it to your laptop's hard drive, and boot up Print111OS directly if you wanted! However, it's much easier to work with a virtual machine or PC emulator.
An emulator is just a program that emulates, or mimics, the behavior of a full hardware platform. Thus, a PC emulator program essentially pretends that it's a Pentium: it emulates the execution of Intel x86 instructions. It can also emulate other PC hardware. For example, the emulator can connect the emulated hard disk drive to a normal file in your home directory; when the program inside the emulator reads a sector from the disk, the emulator will simply read 512 bytes from the file. PC emulators are much slower than real hardware, since they do all of the regular CPU's job in software -- not to mention the disk controller's job, the console's job, and so forth. However, debugging with an emulator is a whole lot friendlier, and you can't screw up your machine!
We've used two PC emulators. The Bochs emulator has pretty nice debugging support, and it is the only emulator that appears to work on the weird machines in the Linux lab. The QEMU package is fast and sleek; if you work on your own machine, try QEMU. If you're interested in working from home, you can download the source for QEMU and/or Bochs and install your own copy. Precompiled binaries for Windows and Mac OS X are available too.
You will also need a copy of GCC that compiles code for an x86 ELF target. ELF, or Executable and Linkable Format, is a particular format for storing machine language programs on disk. Recent Linux PCs have the right compiler already set up. However, if you want to work on other platforms, or on Windows, you'll need a cross-compiler: a version of GCC that runs on your machine, but generates binaries for WeensyOS. Instructions for building such a cross-compiler are available here.
Now that you've got all the software set up (or you've just decided to use the Linux lab), it's time to download WeensyOS and take it out for a spin.
Download and unpack the source for weensyos1.
If you've never unpacked source code before, don't worry; the process is very easy. Unix source code is distributed in packed collections informally called tarballs, after the tar (Tape ARchive) program that parses the format. Think of a tarball as a Zip archive: a single file that contains compressed versions of a set of other files. Tarballs have the suffix .tar or, more frequently, .tar.gz or .tgz. These latter suffixes indicate that the tarball has been compressed. The GNU tar program knows how to uncompress the tarball and extract all its comments. Here's the command:
% gtar xzf weensyos1.tar.gz
This should unpack the tarball into the weensyos1 directory.
% ls weensyos1
COPYRIGHT elf.h passwdos-boot.c passwdos.h
GNUmakefile mergedep.pl passwdos-c.c print111os-boot.c
bootstart.S mkbootdisk.pl passwdos-p.c types.h
conf mmu.h passwdos-yield.S x86.h
%
(If you have no gtar program, try tar instead. If tar complains about the z option, run gunzip weenyos1.tar.gz; tar xf weenyos1.tar.)
Now that you've unpacked the source, it's time to give the OSes a whirl.
Change into the weensyos1 directory and run the gmake program.
Gmake, in case you haven't heard of it, is one of a family of make programs that simplify the process of building software projects. The user writes a set of rules, called a Makefile, that tells the make program what to build. For example, a Makefile might say, "to compile a C program, run the gcc compiler; and by the way, I want to compile the program named hello, which depends on the C source file hello.c". Makefiles can be quite simple, although most medium-to-large projects have complex Makefiles. You'll be using a couple simple Makefiles in the labs.
The WeensyOS Makefile (well, GNUmakefile) builds two hard disk images when it runs. The first image, print111os.img, contains the Print111OS; it is built from the bootstrapping code in bootstart.S and the actual Print-111 program, which is in print111os-boot.c. The second image, passwdos.img, contains the PasswdOS. Since PasswdOS contains two processes, it is a bit more complex than Print111OS; five files are compiled to create passwdos.img, namely bootstart.S, passwdos-boot.c (a simple boot loader), passwdos-p.c (the password printer), passwdos-c.c (the password checker), and passwdos-yield.S (some assembly language glue code for transferring control between the processes).
Gmake's output should look something like this:
% gmake
+ as bootstart.S
+ cc print111os-boot.c
+ ld obj/bootstart.o
+ mk print111os.img
+ cc passwdos-boot.c
+ ld obj/bootstart.o
+ cc passwdos-p.c
+ as passwdos-yield.S
+ ld obj/passwdos-p.o
+ cc passwdos-c.c
+ ld obj/passwdos-c.o
+ mk passwdos.img
%
Now that you've built the OS disk images, it's time to run them! We've made it very easy to boot a given disk image; just run this command:
% gmake run-print111os
This will start up Bochs, but not yet the emulated computer. (This is because Bochs is giving you a chance to set breakpoints on the emulated machine.) To start the emulated computer, type "c":
<bochs:1> c
After a moment you should see a window like this!
![[Print111OS]](print111os-bochs.gif)
To quit Bochs, click the "Power" button in the upper-right corner. (Pretty funny, huh?) Then run the PasswdOS with gmake run-passwdos; it should print out "Y" instead of "111!".
QEMU Note. If you're running QEMU instead of Bochs, run the
Print111OS with qemu -hda print111os.img, and the
PasswdOS with qemu -hda passwdos.img. (The
-hda option stands for Hard Disk A.) QEMU doesn't have a
funky power button; just hit Control-C in the terminal to quit.
You're now ready to start learning about the OS code!
The natural place to start is the first code that gets run. That's the boot loader -- a small piece of code, residing in the hard disk's first sector, that's responsible for loading everything else. As we saw in class, each PC contains a little bit of firmware code, burned in to stable memory (either ROM or flash memory). This code is responsible for initializing the computer just enough so that other software -- namely, the OS itself -- can start. The firmware is called the BIOS, which stands for Basic Input/Output System. How does the BIOS bootstrap the operating system? Simple: The BIOS searches disks attached to a system for a valid boot sector. This is a sector ending with a two-byte magic number (see the code to find out which number). Once a boot sector is found, the BIOS reads it into memory at address 0x7C00, then jumps to address 0x7C00. This program is expected to be a boot loader, which takes whatever steps are necessary to load the rest of the kernel; and the BIOS is no longer in control.
In WeensyOS, we arrange the boot sector so that control is transferred to start in bootstart.S. Though simple, this code needs to jump through a couple hoops, since the BIOS tries to be compatible with operating systems written for 20+-year-old 8086 processors. Once it's done, it passes control on to another routine -- namely, bootmain.
Read the comment at the head of bootstart.S. This assembly-language file starts the boot process. Don't worry about the assembly language itself!! Just read and understand the first comment.
Understand the comments and the code in print111os-boot.c.
Exercise 1. Answer the following question: Why are we lucky that the print111os-boot.c program is well under 510 bytes in length?
Exercise 2. Change the print111os-boot.c program so that it fills up the console with stars, not spaces. Run and test your operating system.
Exercise 3. Change the print111os-boot.c program so that it prints "111!" in red-on-white text. Run and test your operating system.
Hint: Check out this document on the "VGA Programming Model". In particular, search for "Figure 12" and read the text that follows.
The code you hand in should follow both Exercise 1 and Exercise 2, so it
should print 111! in red-on-white against a background of
stars.
Exercise 4. Compare and contrast the two different methods used in print111os-boot.c to access hardware. How and why do lines 29-36 differ from lines 48-53? What are the names of these two hardware interaction methodologies?
Hint: Take a look at the terms used in Section 8 of the 80386 Programmer's Manual.
The Print111 version of WeensyOS is really small: it supports only one process! There's nothing wrong with such a simple operating system; in fact, operating systems for embedded processors, like the things that run in your toaster or your car, often support exactly one process. But of course, it is far more powerful to support multiple processes at a time. This makes much more efficient use of the computer's resources; for example, while one process waits for data to be retrieved from a disk, another process can go ahead with its work.
The PasswdOS is about the simplest multi-process operating system you
can imagine.
It supports two processes, a password printer and a password
checker.
The printer writes a password to the checker.
The checker compares that password to the "correct" password; if they
agree, it prints "Y" to the screen, and if they don't, it
prints "N".
The processes in PasswdOS use cooperative multitasking. That is, processes give up control voluntarily. If one of the processes went into an infinite loop, the machine would entirely stop. This contrasts with preemptive multitasking, in which a trusted OS component (the kernel) can force an uncooperative process to give up control. Preemptive multitasking is more robust than cooperative multitasking, meaning it's more resilient to errors. However, it is slightly more complex, and preemption is by definition slower than cooperative multitasking. All modern operating systems use preemptive multitasking, but don't forget that cooperative multitasking exists: we will see how to use it in your own programs.
Because PasswdOS uses cooperative multitasking, it does not need an operating system kernel! A kernel is required in a system with preemptive multitasking; there has to be a trusted component that takes control and shuts down untrusted processes. But not here. PasswdOS does not, in fact, have a kernel; after the OS boots, it runs just the two processes' code (the printer and the checker).
Of course, we still have to boot the OS. PasswdOS uses a separate
bootloader, just like today's PC OSes. That bootloader simply loads the
printer and the checker into memory, then transfers control to the printer.
If you're curious, see passwdos-boot.c.
The memory layout for PasswdOS looks like this. (Bar widths are not to scale.)
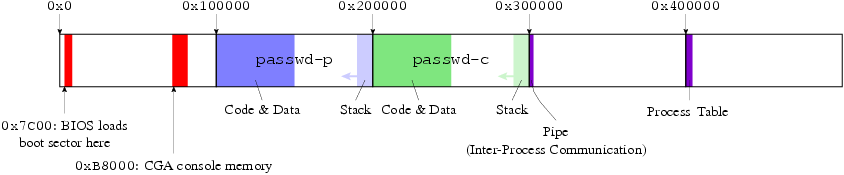
PasswdOS uses a single memory space. That is, all its processes -- the printer and the checker -- must share the same memory space. Thus, the two processes must load at different addresses. We load the printer at address 0x100000, or 1 megabyte (the beginning of the PC's "extended memory"*). Just to keep things simple, we load the checker at address 0x200000; but most of the megabyte of memory between 0x100000 and 0x200000 is unused, since the printer needs only 156 bytes. A real OS would avoid wasting memory like this.
The printer and checker programs are machine code, of course, and machine code can contain memory addresses. So we must ensure that these programs use different regions of memory, or they'd clobber each other. This is the linker's job. Linking is the last stage in compiling a program.** The compiler and assembler turn source code into object files, which contain machine code, but the processor can't interpret object files directly. This is because most programs are built from multiple pieces: multiple source files plus some libraries: trying to run just one piece alone doesn't make sense! So the linker combines all the important object files and libraries into an executable that the processor can run. This requires making sure that jumps from one object file to another, and references to different functions and data, use the right addresses. So the linker must rearrange the object files in a process called relocation.
The PasswdOS uses relocation to enforce the memory layout above, and
thus to make sure that no two processes collide.
We tell the linker explicitly to relocate the printer to address 0x100000,
and the checker to address 0x200000. Check out the
GNUmakefile if you want to see how.
(*The term "extended memory" is used because the original 8086 processor could not access addresses above 1 megabyte.)
(**The linker isn't the last step in modern operating systems that
support shared libraries. Another relocation step happens at load
time, when the process is loaded into memory. On Linux, the dynamic
linker/loader is in charge of this: man ld.so for more
info.)
Of course, allocating space for the code is necessary, but not sufficient. We still need a place for data local to each process -- the process's current instruction pointer, say, or the arguments to its functions.
There are several ways to implement process-local storage, but modern architectures have evolved to support one particularly useful arrangement: the stack. If you've programmed a computer in any language like C, C++, Java, Pascal, Fortran, PHP, or Perl, you've used a stack.
The basic idea is simple. Source code is organized as a set of functions (or procedures). We can execute a function's instructions by calling it. But here's the kicker: every call to a function returns at most once.
This may be so obvious that, when explained, it doesn't seem to make sense. Consider this example:
int add_1(int arg) {
return arg + 1;
}
int add_2(int x) {
int y = add_1(x);
return add_1(y);
}
The add_1 function just adds 1 to its argument.
What happens when we call add_2? Well, it calls
add_1; stores the result in y; then returns the
result of calling add_1 again.
Of course both calls to add_1 will return exactly once!
In most languages, all functions have this property: either they
return exactly once, or they never return at all (maybe by going into an
infinite loop).
What does that mean for local storage? Say we allocate local storage for each called function. Well, if a function returns at most once, then a function's local storage can be recycled (thrown away) as soon as it returns! After the function returns, it essentially ceases to exist. (Of course, the function might be called again, with the same or different arguments; but that will use new local storage.)
This lets us allocate local storage in a very simple, cheap way.
Think of it like a stack of plates, where a plate represents a function's
local storage.
When the processor calls a function, we put a plate onto the stack;
when the topmost function returns, we pop its plate off the stack and break
it into a million pieces.
To allocate or free local storage, then, we can just move a pointer
forward or backward (that is, push or pop a "plate").
For example, here's an outline of the call var = add_2(45),
showing the stack at each step:
| var = ?? | | var = ?? | | var = ?? |
+-----------+ +-----------+ +-----------+
| x = 45 | | x = 45 | | x = 45 |
| y = ?? | | y = ?? | | y = 46 |
-> +-----------+ +-----------+ -> +-----------+
| arg = 45 |
-> +-----------+
(a) on entry (b) first call to (c) after add_1
add_1 returns
| var = ?? | | var = ?? | | var = 47 |
+-----------+ +-----------+ -> +-----------+
| x = 45 | | x = 45 |
| y = 46 | | y = 46 |
+-----------+ -> +-----------+
| arg = 46 |
-> +-----------+
(d) second call to (e) after add_1 (f) after add_2
add_1 returns returns
Notice how each call to add_1 adds a different "plate" to
the stack, and how the pointer -> shifts as different
functions are called.
This is much cheaper than the complex garbage collection algorithms
required to manage a more general memory structure, such as a heap.
And note that stacks even handle recursive functions (functions that call
themselves).
Most architectures have a special register called the stack
pointer that points to the current function's local storage.
On the x86 this register is called %esp.
Stacks tend to grow downward, like the examples we've shown above.
Calling a new function reduces the stack pointer, and returning from
a function increases the stack pointer.
This is because it is more intuitive to refer to local variables with
positive offsets. (For example, in part (a) of the figure, the variable
x might be located at address %esp + 4.)
The x86 has many instructions that refer implicitly to the stack, including
call and ret.
The call function pushes the address of the next instruction
onto the stack, then jumps to a particular address.
The ret instruction undoes the effect of call: it
pops an address from the stack, then jumps to that instruction.
So we need to allocate a stack for each process. Where? Well, stacks grow downward; so we simply allocate the printer's stack at the top of its memory block (0x200000), and the checker's stack at the top of its memory block (0x300000). This is good enough.
Note that some programming languages, such as Scheme, let functions
return more than once.
These languages can't be implemented with a simple stack.
There are exceptions to the rule even in C -- the setjmp
function, for example, can return more than once -- but those exceptions
are carefully tailored to be compatible with a stack.
Exercise 5. Change both the printer and the
checker to use password "111!" instead of the current
"111". Verify that the checker still prints
"Y".
Despite all this, there is one serious problem with our "password checking OS": the password printer and the password checker share the same memory space, without protection. This means that the printer can cheat -- either by snooping into the checker's memory space, or more actively, by messing around with the checker's memory space. Modern operating systems solve this issue by providing virtual memory protection -- processes can't snoop on each other's memory without permission. But in the next problem, you'll see how devious cheaters can be first hand.
Y", even though
the printer "knows" the wrong password. To test this, change the printer's
code to use password "666", but do NOT change the checker's
code or its good_password (which should be
"111!"). Despite this, the checker should print
"Y" when you run the PasswdOS.There are many ways for the printer cheat. Here are just a few:
good_password will remain unchanged;
it just won't be used.Y" no matter
what password it gets.Y".And, of course, there are others (some simpler than any of these). Choose whichever one you like and implement it. Be creative!
Note that the printer doesn't necessarily have to print the incorrect
password to the checker. But you must not hard code the correct password
into the printer in any way. If you change the checker's
good_password to another value, the printer should still cheat
its way to a "Y" answer.
Many cheating mechanisms require that the printer know where the
checker's code and data are stored in memory.
If you wanted to blow my (and your) mind, the printer could
reverse-engineer this information by tracing the checker's
executable instructions!
But it's much easier to just look this information up.
Take a look at obj/passwdos-c.sym and
obj/passwdos-c.asm.
(April 14: If you don't see obj/passwdos-c.sym, download
weensyos1.tar.gz again, and use
the new GNUmakefile.)
The .sym file tells you exactly which memory addresses are
used for each program object. For example:
00200000 T getch 00200034 T strcmp 00200064 T write_char 002000bc T start 00200118 T _yield 00200128 t _yield2 00210000 D good_password 00210004 A __bss_start 00210004 A _edata 00210004 A _end
This says that the "good_password" symbol is located at
address 0x210000. The .asm file shows you the process's
assembly language code, along with memory addresses, interleaved with the C
code that corresponds. For example:
*PIPEBUF = 0;
200028: c6 05 00 00 30 00 00 movb $0x0,0x300000
This says exactly how the C line ("*PIPEBUF = 0;") is
implemented in machine language. You might use this file, combined with
experimental changes to passwdos-c.c itself, to track down
exactly which instructions the printer should change, and how.
The following functions might be useful, if you haven't done much of this kind of C programming before. You could change them in the obvious ways to read and write integers and even bigger structures.
#include "types.h" // for the definition of 'uint32_t'
unsigned char
read_byte(uint32_t address)
// Returns the byte stored in memory at the given 'address'.
{
return *((unsigned char *) address);
}
void
write_byte(uint32_t address, unsigned char byte)
// Writes 'byte' into memory at the given 'address'.
{
*((unsigned char *) address) = byte;
}
// Example:
write_byte(0x7C00, 255); // will write 255 into address 0x7C00
Exercise 6 will make Exercise 5 somewhat redundant (except that the
checker will nominally check for "111!"); don't worry about
it.
This completes the problem set.