![[Kernel, courtesy IowaFarmer.com CornCam]](kernel.jpg)
CS 235 Advanced Operating Systems, Fall 2005
Lab 5: File System and Shell
Handed out Tuesday, November 30, 2005
Due Friday, December 16, 2005
Introduction
In this lab, you will implement a simple disk-based file system, client-side file descriptors, and a Unix-like command shell! The file system itself will be implemented in microkernel fashion, outside the kernel but within its own user-space environment. Other environments access the file system by making IPC requests to this special file system environment.
Getting Started
Download our reference code for lab 5 from lab5.tar.gz and untar it, then merge it into your CVS repository as you did for the previous labs. (See the CVS hints.)
The main new component for this lab is the file system server, located in
the new fs directory. Scan through all the files in this
directory to get a feel for what's new. Also, there are some new file
system-related source files in the user and lib
directories, particularly lib/fsipc.c,
lib/file.c, and new global header
files inc/fs.h and inc/fd.h. Scan through
all of these files.
You should run the pingpong, primes, and forktree test cases from lab 4
again after merging in the new lab 5 code. You will need to temporarily
comment out the ENV_CREATE line that starts fs/fs
to avoid Bochs panicking because fs/fs does some I/O. If your
lab 4 code doesn't contain any bugs, the test cases should run fine. Don't
proceed until they work.
Lab Requirements
You will need to do all of the regular exercises described in the lab. Please attempt at least one challenge problem, but this is not required. If you do complete it, provide a short (e.g., one or two paragraph) description of what you did. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. There is no need to answer any questions this time, just write up your challenges. Place the write-up in a file called answers.txt (plain text) or answers.html (HTML format) in the top level of your lab5 directory before handing in your work to CourseWeb.
File system preliminaries
The file system you will work with is much simpler than most "real" file systems, but it is powerful enough to provide the standard "basic" features: creating, reading, writing, and deleting files organized in a hierarchical directory structure.
We are (for the moment anyway) developing only a "single-user" operating system, which provides protection sufficient to catch bugs but not to protect multiple mutually suspicious users from each other. Our file system therefore does not support the UNIX notions of file ownership or permissions. Our file system also currently does not support hard links, symbolic links, time stamps, or special device files like most UNIX file systems do.
On-Disk File System Structure
Most UNIX file systems divide available disk space
into two main types of regions:
inode regions and data regions.
UNIX file systems assign one inode to each file in the file system;
a file's inode holds critical meta-data about the file
such as its stat attributes and pointers to its data blocks.
The data regions are divided into much larger (typically 8KB or more)
data blocks, within which the file system stores
file data and directory meta-data.
Directory entries contain file names and pointers to inodes;
a file is said to be hard-linked
if multiple directory entries in the file system
refer to that file's inode.
Since our file system will not support hard links,
we do not need this level of indirection
and therefore can make a convenient simplification:
our file system will not use inodes at all,
but instead we will simply store all of a file's (or sub-directory's) meta-data
within the (one and only) directory entry describing that file.
Both files and directories logically consist of a series of data blocks,
which may be scattered throughout the disk
much like the pages of an environment's virtual address space
can be scattered throughout physical memory.
The file system allows user processes
to read and write the contents of files directly,
but the file system handles all modifications to directories itself
as a part of performing actions such as file creation and deletion.
Our file system does, however, allow user environments
to read directory meta-data directly
(e.g., with read and write),
which means that user environments can perform directory scanning operations
themselves (e.g., to implement the ls program)
rather than having to rely on additional special calls to the file system.
The disadvantage of this approach to directory scanning,
and the reason most modern UNIX variants discourage it,
is that it makes application programs dependent
on the format of directory meta-data,
making it difficult to change the file system's internal layout
without changing or at least recompiling application programs as well.
Sectors and Blocks
Most disks cannot perform reads and writes at byte granularity, but can only perform reads and writes in units of sectors, which today are almost universally 512 bytes each. File systems actually allocate and use disk storage in units of blocks. Be wary of the distinction between the two terms: sector size is a property of the disk hardware, whereas block size is an aspect of the operating system using the disk. A file system's block size must be at least the sector size of the underlying disk, but could be greater.
The original UNIX file system used a block size of 512 bytes, the same as the sector size of the underlying disk. Most modern file systems use a larger block size, however, because storage space has gotten much cheaper and it is more efficient to manage storage at larger granularities. Our file system will use a block size of 4096 bytes, conveniently matching the processor's page size.
Superblocks
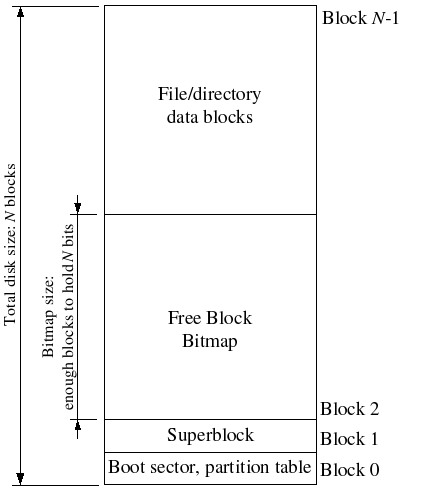
File systems typically reserve certain disk blocks, at "easy-to-find" locations on the disk such as the very start or the very end, to hold meta-data describing properties of the file system as a whole, such as the block size, disk size, any meta-data required to find the root directory, the time the file system was last mounted, the time the file system was last checked for errors, and so on. These special blocks are called superblocks.
Our file system's superblock layout is defined by struct Super in inc/fs.h.
The file system superblock will always occupy block 1 on the disk;
boot loaders and partition tables use Block 0, so
most file systems don't use the very first disk block.
Most "real" file systems maintain multiple superblocks,
replicated throughout several widely-spaced regions of the disk,
so that if one of them is corrupted
or the disk develops a media error in that region,
the other superblocks can still be found and used to access the file system.
The Block Bitmap: Managing Free Disk Blocks
In the same way that the kernel must manage the system's physical memory
to ensure that a given physical page is used for only one purpose at a time,
a file system must manage the blocks of storage on a disk
to ensure that a given disk block is used for only one purpose at a time.
In pmap.c you keep the Page structures
for all free physical pages
on a linked list, page_free_list,
to keep track of the free physical pages.
In file systems it is more common to keep track of free disk blocks
using a bitmap rather than a linked list,
because a bitmap is more storage-efficient than a linked list
and easier to keep consistent.
Searching for a free block in a bitmap can take more CPU time
than simply removing the first element of a linked list,
but for file systems this isn't a problem
because the I/O cost of actually accessing the free block after we find it
dominates for performance purposes.
To set up a free block bitmap, we reserve a contiguous region of space on the disk large enough to hold one bit for each disk block. For example, since our file system uses 4096-byte blocks, each bitmap block contains 4096*8=32768 bits, or enough bits to describe 32768 disk blocks. In other words, for every 32768 disk blocks the file system uses, we must reserve one disk block for the block bitmap. A given bit in the bitmap is set if the corresponding block is free, and clear if the corresponding block is in use. The block bitmap in our file system always starts at disk block 2, immediately after the superblock. For simplicity we will reserve enough bitmap blocks to hold one bit for each block in the entire disk, including the blocks containing the superblock and the bitmap itself. We will simply make sure that the bitmap bits corresponding to these special, "reserved" areas of the disk are always clear (marked in-use).
File Meta-data
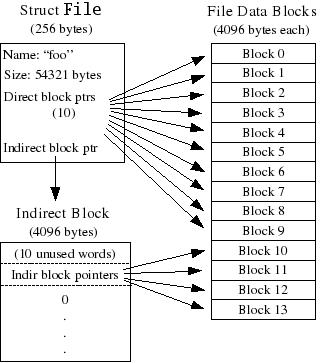
The layout of the meta-data describing a file in our file system
is described by struct File in inc/fs.h.
This meta-data includes the file's name, size,
type (regular file or directory),
and pointers to the blocks comprising the file.
Unlike in most "real" file systems,
for simplicity we will use this one File structure
to represent file meta-data as it appears
both on disk and in memory.
Some of the fields in the structure (currently, only f_dir)
are only meaningful while the File structure is in memory;
whenever we read a File structure from disk into memory,
we clear these fields.
The block array in struct File contains space
to store the block numbers
of the first 10 (NDIRECT) blocks of the file,
which we call the file's direct blocks.
For small files up to 10*4096 = 40KB in size,
this means that the block numbers of all of the file's blocks
will fit directly within the File structure itself.
For larger files, however, we need a place
to hold the rest of the file's block numbers.
For any file greater than 40KB in size, therefore,
we allocate an additional disk block, called the file's indirect block,
to hold up to 4096/4 = 1024 additional block numbers.
To keep bookkeeping simple, we leave the first 10 numbers in the indirect block
unused. Thus, the 10th block number is the 10th slot in the indirect block
(rather than the 0th, as might be done if we were being very space-efficient).
Our file system therefore allows files to be up to 1024 blocks,
or four megabytes, in size.
To support larger files,
"real" file systems typically support
double- and triple-indirect blocks as well.
Directories versus Regular Files
A File structure in our file system
can represent either a regular file or a directory;
these two types of "files" are distinguished by the type field
in the File structure.
The file system manages regular files and directory-files
in exactly the same way,
except that it does not interpret the contents of the data blocks
associated with regular files at all,
whereas the file system interprets the contents
of a directory-file as a series of File structures
describing the files and subdirectories within the directory.
The superblock in our file system
contains a File structure
(the root field in struct Super),
which holds the meta-data for the file system's root directory.
The contents of this directory-file
is a sequence of File structures
describing the files and directories located
within the root directory of the file system.
Any subdirectories in the root directory
may in turn contain more File structures
representing sub-subdirectories, and so on.
Part 1: The File System Server
Disk Access
The file system server in our operating system needs to be able to access the disk, but we have not yet implemented any disk access functionality in our kernel. Instead of taking the conventional "monolithic" operating system strategy of adding an IDE disk driver to the kernel along with the necessary system calls to allow the file system to access it, we will instead implement the IDE disk driver as part of the user-level file system environment. We will still need to modify the kernel slightly, in order to set things up so that the file system environment has the privileges it needs to implement disk access itself.
It is easy to implement disk access in user space this way as long as we rely on polling, "programmed I/O" (PIO)-based disk access and do not use disk interrupts. It is possible to implement interrupt-driven device drivers in user mode as well (the L3 and L4 kernels do this, for example), but it is more difficult since the kernel must field device interrupts and dispatch them to the correct user-mode environment.
The x86 processor uses the IOPL bits in the EFLAGS register to determine whether protected-mode code is allowed to perform special device I/O instructions, such as IN and OUT. The IOPL bits equal the minimum (i.e. numerically highest) privilege level allowed to perform IN and OUT instructions, so if those bits are 0, only the kernel can execute INs and OUTs. All of the IDE disk registers we need to access are located in the x86's I/O space (rather than memory-mapped I/O space), so to let the file system environment access the disk, all we need to do is manipulate the IOPL bits. But no other environment should be able to access I/O space.
To keep things simple, from now on we will arrange things so that the file system is always user environment 1. (Recall that the idle loop is always user environment 0.)
Exercise 1.
Modify your kernel's environment initialization function,
env_alloc in env.c,
so that it gives environment 1 I/O privilege,
but never gives that privilege to any other environment.
Use |
Do you have to do anything else to ensure that this I/O privilege setting is saved and restored properly when you subsequently switch from one environment to another? Make sure you understand how this environment state is handled.
Read through the files in the new fs directory in the source tree.
The file fs/ide.c implements our minimal PIO-based disk driver.
The file fs/serv.c contains the umain function
for the file system server.
Note that the new .bochsrc file in this lab
sets up Bochs to use the file kern/bochs.img
as the image for disk 0 (typically "Drive C" under DOS/Windows) as before,
and to use the (new) file obj/fs/fs.img
as the image for disk 1 ("Drive D").
In this lab your file system should only ever touch disk 1;
disk 0 is used only to boot the kernel.
If you manage to corrupt either disk image in some way,
you can reset both of them to their original, "pristine" versions
simply by typing:
$ rm obj/kern/bochs.img obj/fs/fs.img $ gmake
| Challenge! Implement interrupt-driven IDE disk access, with or without DMA. You can decide whether to move the device driver into the kernel, keep it in user space along with the file system, or even (if you really want to get into the microkernel spirit) move it into a separate environment of its own. |
The Block Cache
In our file system, we will implement a very simplistic "buffer cache" with the help of the processor's virtual memory system. Our file system will be limited to handling disks of size 3GB or less. We reserve a large, fixed 3GB region of the file system environment's address space, from 0x10000000 (DISKMAP)
up to 0xD0000000 (DISKMAP + DISKSIZE),
to map disk block pages.
In particular, disk block B is always mapped at address
DISKMAP + B*PGSIZE.
If that address is unmapped, than disk block B is not in
memory.
For example,
disk block 0 is mapped at virtual address 0x10000000
whenever it is in memory,
disk block 1 is mapped at virtual address 0x10001000,
and so on.
We can tell whether a block is mapped by consulting vpd and vpt.
Since our file system environment has its own virtual address space independent of the virtual address spaces of all other environments in the system, and the only thing the file system needs to do is to implement file access, it is reasonable to reserve most of the file system environment's address space in this way. It would be problematic for a "real" file system implementation on a 32-bit machine to do this of course, since most disks available today are already larger than 3GB. Such a buffer cache management approach may still be reasonable on a machine with a 64-bit address space.
Exercise 2.
Implement the
The
Use |
The Block Bitmap
After fs_init calls read_super
(which we have provided)
to read and check the file system superblock,
fs_init calls read_bitmap
to read and perform basic validity checking
on the disk's block bitmap.
For speed and simplicity,
our file system will always keep the entire block bitmap in memory.
Exercise 3.
Implement read_bitmap.
It should check that all of the "reserved" blocks in the file system --
block 0, block 1 (the superblock),
and all the blocks holding the block bitmap itself --
are marked in-use.
Use the provided block_is_free routine for this purpose.
You may simply panic if the file system is invalid.
Use |
Exercise 4.
Use block_is_free as a model
to implement alloc_block_num,
which scans the block bitmap for a free block,
marks that block in-use,
and returns the block number.
When you allocate a block, you should immediately flush the
changed bitmap block to disk with write_block, to help
file system consistency.
Use |
File Operations
We have provided a variety of functions in fs/fs.c
to implement the basic facilities you will need
to interpret and manage File structures,
allocate and/or find a given block of a file,
scan and manage the entries of directory-files,
and walk the file system from the root
to resolve an absolute pathname.
Read through the code in fs/fs.c
and make sure you understand what each function does
before proceeding.
Exercise 5.
Fill in the remaining functions in fs/fs.c
that implement "top-level" file operations:
file_open,
file_get_block,
file_truncate_blocks,
and file_flush.
Use |
You may notice that there are two operations conspicuously absent
from this set of functions implementing "basic" file operations:
namely, read and write.
This is because our file server
will not implement read and write operations directly
on behalf of client environments,
but instead will use our kernel's IPC-based page remapping functionality
to pass mapped pages to file system clients,
which these client environments can then read and write directly.
The page mappings we pass to clients will be
exactly those pages that represent in-memory file blocks
in the file system's own buffer cache, fetched via
file_get_block.
You will see the user-space read and write in part 2.
| Challenge! The file system code uses synchronous writes to keep the file system fairly consistent in the event of a crash. Implement soft updates instead. |
Client/Server File System Access
Now that we have implemented the necessary functionality within the file system server itself, we must make it accessible to other environments that wish to use the file system. There are two pieces of code required to make this happen: client stubs and server stubs. Together, they form a remote procedure call, or RPC, abstraction, where we make IPC-based communication across address spaces appear as if they were ordinary C function calls within client applications.
The client stubs,
which we have implemented for you and provided in lib/fsipc.c,
implement the "client side" of the file system server's IPC protocol.
Like fork,
these functions are linked into each application
that wants to use the file system.
When a client application needs to communicate with the file server,
it will use the client stubs to perform this communication.
Each client stub uses ipc_send to send a message to the server,
and then uses ipc_recv to wait for a reply to its request.
Exercise 6.
The server stubs are located in the file server itself,
implemented in Use |
Part 2: File System Access from Client Environments
Client-Side File Descriptors
Although we can write applications
that directly use the client-side stubs in lib/fsipc.c
to communicate with the file system server and perform file operations,
this approach would be inconvenient for many applications
because the IPC-based file server interface is still somewhat "low-level"
and does not provide conventional read/write operations.
To read or write a file,
the application would first have to reserve a portion of its address space,
map the appropriate blocks of the file into that address region
by making requests to the file server,
read and/or change the appropriate portions of those mapped pages,
and finally send a "close" request to the file server
to ensure that the changes get written to disk.
We will write library routines
to perform these tasks on behalf of the application,
so that the application can use conventional UNIX-style file access operations
such as read, write, and seek.
The client-side code
that implements these UNIX-style file operations
is located in lib/fd.c and lib/file.c.
lib/fd.c contains functions
to allocate and manage generic Unix-like file descriptors,
while lib/file.c implements file descriptors
referring to files managed by the file server.
We have implemented most of the functions in both of these files for you;
the only ones you need to fill in are
fd_alloc and fd_lookup in lib/fd.c,
and open and close in lib/file.c.
The file descriptor layer defines two new virtual address regions within each application environment's address space. The first is the file descriptor table area, starting at address FDTABLE, reserves one 4KB page worth of address space for each of the up to MAXFD (currently 32) file descriptors the application can have open at once. At any given time, a particular file descriptor table page is mapped if and only if the corresponding file descriptor is in use.
The second new virtual address region is the file mapping area, starting at virtual address FILEBASE. Like the file descriptor table, the file mapping area is organized as a table indexed by file descriptor, except the "table entries" in the file mapping area consist of 4MB rather than 4KB of address space. In particular, for each of the MAXFD possible file descriptors, we reserve a fixed 4MB region in the file mapping area in which to map the contents of currently open files. Since our file server only supports files of up to 4MB in size, these client-side functions are not imposing any new restrictions by only reserving 4MB of space to map the contents of each open file.
Exercise 7.
Implement fd_alloc and fd_lookup.
fd_alloc finds an unused file descriptor number,
and returns a pointer to the corresponding file descriptor table entry.
Similarly, fd_lookup checks
to make sure a given file descriptor number is currently active,
and if so returns a pointer to the corresponding file descriptor table entry.
|
Exercise 8.
Implement open.
It must find an unused file descriptor
using fd_alloc(),
make an IPC request to the file server to open the file,
and then map all the file's pages
into the appropriate reserved region of the client's address space.
Be sure your code fails gracefully
if the maximum number of files are already open,
or if any of the IPC requests to the file server fail.
Use |
Exercise 9.
Implement
Use |
| Challenge! Add support to the file server and the client-side code for files greater than 4MB in size. |
| Challenge! Make the file access operations lazy, so that the pages of a file are only mapped into the client environment's address space when they are touched. Be sure you can still handle error conditions gracefully, such as the file server running out of memory while the application is trying to read a particular file block. |
| Challenge! Change the file system to keep most file metadata in Unix-style inodes rather than in directory entries, and add support for hard links between files. |
| Challenge! Change the file system design to support more than one file descriptor per page. |
Part 3: Spawning Processes from the File System
In this exercise, you'll extend spawn from Lab 4
to load program images from the file system as well as
from kernel binary images.
If spawn is passed a binary name like "/ls" that
begins with a slash, it will read the program data from disk;
otherwise, it will read the program data from the kernel.
Luckily, this requires just a couple of changes.
Exercise 10.
Change your |
Exercise 11. Complete the
implementation of Use |
Part 4: A Shell
In this part of the lab, you'll extend JOS to handle everything necessary to support a shell. We've done a lot of the work for you, but you must (1) make it possible to share file descriptors across environments, (2) clean up a couple loose ends, and (3) implement file redirection in the shell.
Sharing pages between environments
We would like to share file descriptor state across
fork and spawn, but file descriptor state is kept
in user-space memory. Right now, on fork, the memory
will be marked copy-on-write,
so the state will be duplicated rather than shared.
(This means that running "(date; ls) >file" will
not work properly, because even though date updates its own file offset,
ls will not see the change.)
On spawn, the memory will be
left behind, not copied at all. (Effectively, the spawned environment
starts with no open file descriptors.)
We will change both fork and spawn to know that
certain regions of memory are used by the "library operating system" and
should always be shared. Rather than hard-code a list of regions somewhere,
we will set an otherwise-unused bit in the page table entries (just like
we did with the PTE_COW bit in fork).
We have defined a new PTE_SHARE bit
in inc/lib.h.
If a page table entry has this bit set, then by convention,
the PTE should be copied directly from parent to child
in both fork and spawn.
Note that this is different from marking it copy-on-write:
as described in the first paragraph,
we want to make sure to share
updates to the page.
Exercise 12.
Change your duppage code in lib/fork.c to follow
the new convention. If the page table entry has the PTE_SHARE
bit set, just copy the mapping directly, regardless of whether it is
marked writable or copy-on-write.
(This could be a one-line change, depending on your current code!)
|
Exercise 13.
Change spawn in lib/spawn.c to propagate
PTE_SHARE pages. After it finishes
setting up the child virtual address space but before it marks the
child runnable, it should call copy_shared_pages
to loop through all the page table entries in the current process
(just like fork did), copying any
mappings that have the PTE_SHARE bit set.
You'll need to modify spawn so that it calls copy_shared_pages
(a one-line change), and implement copy_shared_pages
itself (more than one line). Make sure that you copy the shared pages
very near the end of the function, after closing the file descriptor corresponding to the ELF binary! (Why?)
|
Use gmake run-testpteshare to check that your code is
behaving properly.
You should see lines that say "fork handles PTE_SHARE right"
and "spawn handles PTE_SHARE right".
Exercise 14.
Change your definition of serve_map in the file server's
fs/serv.c so that
all the file descriptor table pages and the file data pages get mapped
with PTE_SHARE.
(This could be a one-line change, depending on your current code!)
|
Use gmake run-testfdsharing to check that file descriptors are shared
properly.
You should see lines that say "read in child succeeded" and
"read in parent succeeded".
Pipes
Pipes and the console are both I/O stream interfaces.
This means that they support reading and/or writing,
but not file positions.
Like Unix, JOS represents these streams using file descriptors.
To support this, the file descriptor subsystem
uses a simple virtual file system layer,
implemented by struct Dev,
so that disk files, console files, and pipes all implement the same file
descriptor functions.
A pipe is a shared data buffer accessed via two file descriptors, one
for writing data into the pipe and one for reading data out of it.
Unix command lines like "ls | sort" use pipes. The shell
creates a pipe, hooks up ls's standard output to the write end
of the pipe, and hooks up sort's standard input to the read
end of the pipe. As a result, ls's output is processed by
sort.
You may want to read the
pipe manual page for background, and the pipe
section of Dennis Ritchie's UNIX history paper for interesting
history.
In Unix-like designs, each pipe's shared data buffer is stored in the
kernel. Of course, this is not how we implement pipes on an exokernel!
Your library operating system represents a pipe, including its shared
buffer, by a single struct Pipe.
The struct Pipe is stored on its own page to make sharing
easier, and mapped into the file mapping area of both the reading and the
writing file descriptor.
Here's the structure:
#define PIPEBUFSIZ 32
struct Pipe {
off_t p_rpos; // read position
off_t p_wpos; // write position
uint8_t p_buf[PIPEBUFSIZ]; // shared buffer
};
This is a simple lock-free queue structure. The pipe starts in this state:
p_rpos = 0 ---+
p_wpos = 0 ---|+
VV
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
p_buf: | | | | | | | | | | | | |
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
0 1 2 3 4 5 6 28 29 30 31
The bytes written to the pipe can be thought of as numbered starting
from 0. The write position p_wpos gives the number of the
next byte that will be written, and the read position p_rpos
gives the number of the next byte to be read. After a writer writes "abc" to the pipe, it will enter this state:
p_rpos = 0 ---+
p_wpos = 3 ---|-----------+
V V
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
p_buf: | a | b | c | | | | | | | | | |
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
0 1 2 3 4 5 6 28 29 30 31
Since p_rpos != p_wpos, the pipe contains data. The next
read from the pipe will return the next 3 characters. For example, after
a read() of one byte:
p_rpos = 1 -------+
p_wpos = 3 -------|-------+
V V
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
p_buf: | | b | c | | | | | | | | | |
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
0 1 2 3 4 5 6 28 29 30 31
This data structure is safe for concurrent updates as long as there is a
single reader and a single writer, since only the reader updates
p_rpos and only the writer updates p_wpos.
Since the pipe buffer is not infinite, byte i is stored in
pipe buffer index i % PIPEBUFSIZ. Thus, after a couple reads
and writes, the pipe might enter this state:
p_rpos = 30 ----------------------------------------------+
p_wpos = 33 ------+ |
V V
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
p_buf: | $ | | | | | | | | | | ! | @ |
+---+---+---+---+---+---+---+- ... -+---+---+---+---+
0 1 2 3 4 5 6 28 29 30 31
Note that byte 32 was stored in slot 0.
If p_rpos == p_wpos, the pipe is empty. Any
read call should yield until a writer adds information to the
pipe. Similarly, if p_wpos - p_rpos == PIPEBUFSIZ, the pipe
is full. Any write call should yield until a reader opens up
some space in the pipe.
Closed Pipes
There is a catch -- maybe we are trying to read from an empty pipe but all the writers have exited. Then there is no chance that there will ever be more data in the pipe, so waiting is futile. In such a case, Unix signals end-of-file by returning 0. So will we. To detect that there are no writers left, we could put reader and writer counts into the pipe structure and update them every time we fork or spawn and every time an environment exits. This is fragile -- what if the environment doesn't exit cleanly? Instead we can use the kernel's page reference counts, which are guaranteed to be accurate.
Recall that the kernel page structures are mapped read-only in user
environments. The library function pageref(void *ptr) returns
the number of page table references to the page containing the virtual
address ptr. It works by first examining vpt[]
to find ptr's physical address, then looking up the relevant
struct Page in the UPAGES array and returning its
pp_ref field. So, for example, if fd is a
pointer to a particular struct Fd, pageref(fd)
will tell us how many different references there are to that structure.
Three pages are allocated for each pipe: the struct Fd for
the reading file descriptor rfd, the struct Fd
for the writing file descriptor wfd, and the struct
Pipe p shared by both. The struct Pipe
page is mapped once per file descriptor reference. Thus, the following
equation holds: pageref(rfd) + pageref(wfd) = pageref(p). A
reader can check whether there are any writers left by examining these
counts. If pageref(p) == pageref(rfd), then
pageref(wfd) == 0, and there are no more writers. A writer can
check for readers in the same manner.
Exercise 15. Implement pipes in
lib/pipe.c. We've included the code for reading from
a pipe for you. You must write the code for writing to a pipe, and
the code for testing whether a pipe is closed. Run gmake run-testpipe to check your work; you
should see a line "pipe tests
passed". |
Pipe Races
File descriptor structures use shared memory that is written concurrently by multiple processes. That creepy shiver that just ran up your back is justified: this kind of situation is ripe with race conditions. Our file descriptor code contains many race conditions -- for example, if a multiple processes are reading from the same file descriptor, then updates to the file offset may get lost. But we've made one race condition, concerning pipes, particularly easy to run into.
The race is that the two calls to pageref() in
_pipeisclosed might not happen atomically. If another process
duplicates or closes the file descriptor page between the two calls, the
comparison will be meaningless. To make it concrete, suppose that we
run:
pipe(p);
if (fork() == 0) {
close(p[1]);
read(p[0], buf, sizeof(buf));
} else {
close(p[0]);
write(p[1], msg, strlen(msg));
}
The following might happen:
- The child runs first after the fork.
It closes
p[1]and then tries to read fromp[0]. The pipe is empty, soreadchecks to see whether the pipe is closed before yielding. Inside_pipeisclosed,pageref(fd)returns 2 (both the parent and the child havep[0]open), but then a clock interrupt happens. - Now the kernel chooses to run the parent for a little while.
The parent closes
p[0]and writesmsginto the pipe.Msgis very long, so thewriteyields halfway to let a reader (the child) empty the pipe. - Back in the child,
_pipeisclosedcontinues. It callspageref(p), which returns 2 (the child has a reference associated withp[0], and the parent has a reference associated withp[1]). The counts match, so_pipeisclosedreports that the pipe is closed. Oops.
Run "gmake run-testpiperace2" to see this race
in action. You should see "RACE: pipe appears closed"
when the race occurs.
This race isn't that hard to fix. Comparing the counts can only be
incorrect if another environment ran between when we looked up the
first count and when we looked up the second count. In other words,
we need to make sure that _pipeisclosed executes
atomically. Since it doesn't change any variables, we can simply
rerun it until it runs without being interrupted; the code is so
short that it will usually not be interrupted.
But how can we tell whether our environment has been interrupted?
Simple: by checking the env_runs variable in our
environment structure. Each time the kernel runs an environment, it
increments that environment's env_runs. Thus, user code
can record env->env_runs, do its computation, and
then look at env->env_runs again. If
env_runs didn't change, then the environment was not
interrupted. Conversely, if env_runs did change, then
the environment was interrupted.
Exercise 16.
Whoops! This exercise was done for you in our handout code by mistake.
Change _pipeisclosed to repeat the
check until it completes without interruption.
Print "pipe race avoided\n" when you notice an interrupt
and the check would have returned 1 (erroneously indicating
that the pipe was closed).
|
Run "gmake run-testpiperace2" to check whether
the race still happens. If it's gone, you should not see
"RACE: pipe appears closed", and you should see
"race didn't happen". You should also see plenty of
your "avoided" messages, indicating places where the
race would have happened if you weren't being so careful. (The
number of "avoided" messages depends on the
ips value in your .bochsrc.)
| Challenge! Write a test program that demonstrates one of the other races, such as a race that corrupts file descriptor offsets, or a race between multiple readers of a single pipe. |
| Challenge! Fix all these races! |
The shell itself
Before running your shell, you must enable keyboard interrupts.
Exercise 17. Change
trap in kern/trap.c to call
kbd_intr() every time interrupt number
IRQ_OFFSET+1 occurs. (This should be a three-line
change.)
|
Run gmake xrun-initsh. This will run your kernel inside the
X11 Bochs starting user/initsh,
which sets up the console as file descriptors 0 and 1 (standard input and
standard output), then spawns sh, the shell.
Run ls and cat lorem.
Exercise 18.
The shell can only run simple commands. It has no redirection or pipes.
It is your job to add these. Flesh out user/sh.c.
|
Once your shell is working, you should be able to run the following commands:
echo hello world | cat cat lorem >out cat out cat lorem |num cat lorem |num |num |num |num |num lsfd cat script sh <script
Note that the user library routine printf prints straight
to the console, without using the file descriptor code. This is great
for debugging but not great for piping into other programs.
To print output to a particular file descriptor (for example, 1, standard output),
use fprintf(1, "...", ...). See user/ls.c for examples.
Run gmake run-testshell to test your shell.
Testshell simply feeds the above commands (also found in
fs/testshell.sh) into the shell and then checks that the
output matches fs/testshell.key.
Challenge!
Add more features to the shell.
Some possibilities include:
|
Challenge!
There is a bug in our disk file implementation
related to multiple programs writing to the same file descriptor.
Suppose they are properly sequenced to avoid simultaneous
writes (for example, running "(ls; ls; ls; ls) >file"
would be properly sequenced since there's only one writer at a time).
Even then, this is likely to cause a page fault in one of the
ls instances during a write. Identify the reason
and fix this.
|
This completes the course!