Major Networking Concepts:
- Low overhead transfer -- Sending out data over the network is not resource intensive.
- CPU no longer in control of data transfer -- When reading from a disk, the CPU can control when it gets data. When transferring data over the network, you are dependent on a lot of other machines!
- Failure typical -- Data will be lost or arrive too late and networks go down.
- Adversarial communication typical -- You must assume that the data you receive arrives in the most inconvenient manner. It can be late, fragmented, and completely unexpected; and it might be sent by an attacker, not who you wanted to talk to at all.
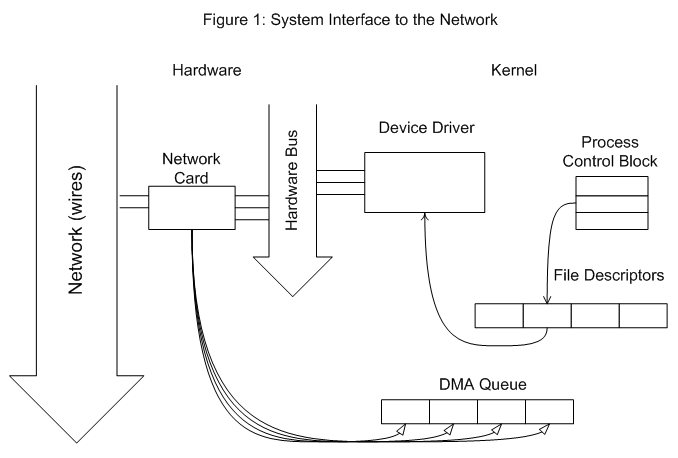
Figure 1 depicts how the kernel and user applications can access the network hardware!
Networking versus the Disk
The network bandwidth is not that much slower than that of a typical disk. However, the transfer is undependable. Furthermore, you will not be able to sustain peak transfer rates over the network.
Why? Here are some factors that slow down network performance:
- Congestion
- Latency
- Loss
- Malicious Attacks
Table 1: Network and Disk Properties
|
|
Network |
Disk |
|
Bandwidth |
1Gb/s |
200MB/s |
|
Granularity |
1500B 'Packets' |
4096B 'Blocks' |
|
Relevance |
Will get unexpected data! |
Always relevant and requested. |
Network Interaction Schemes
Network I/O can be controlled using polling, interrupts, and DMA schemes.
What are some of the advantages and disadvantages of each?
Table 2: I/O Schemes
|
|
Polling |
Interrupts |
DMA |
|
Advantages |
+ Can be efficient if there is a lot of inbound data. |
+ Only bother the CPU when there is data! |
+ 'Faster' Access + Absorb Bursts |
|
Disadvantages |
− The network is undependable and unpredictable so we may have to poll all the time! − Might have trouble with latency if polling rate is too low − May waste CPU cycles polling if there is no data. |
− Can interrupt once per packet, depending on network device! |
− Wastes space storing unwanted packets. |
Lets examine what this means for a the performance of a network application called “Email Forwader” that simply forwards incoming emails messages back out onto the network. Here are some simple assumptions for our analysis of interrupts for the email forwarding application:
- Each message fits entirely in a single packet
- Interrupt once per packet
- Every interrupt invokes a context switch
- Interrupt takes 1 microsecond to process (NB: this is 5 times smaller than we assumed in Lecture 12)
- Programmed I/O operation also takes roughly 1 microsecond
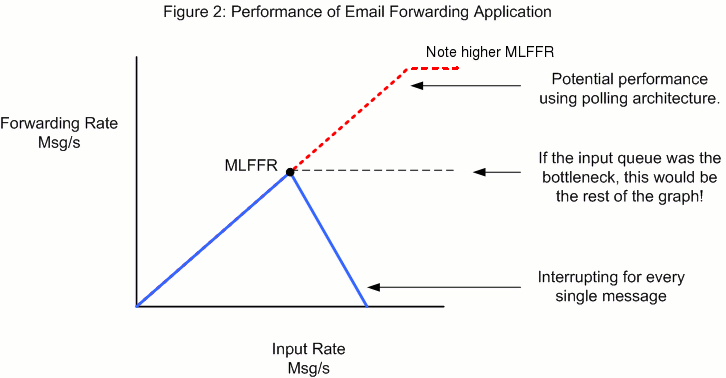
Figure 2 demonstrates a critical problem with interrupt based I/O under heavy load. At first, the program scales linearly with the incoming requests. However, the graph peaks and then starts to degrade toward ZERO! The point of peak performance is known as the Maximum Loss-Free Forwarding Rate or MLFFR.
So what is going on? The CPU is being interrupted by incoming packets before it can finish servicing the packet it is working on. As the rate continues to increase, the CPU is too busy context switching to actually perform useful work. Yes, the output of the program really can grind to a halt! This is a bad situation because it means that we are susceptible to a Denial of Service Attack. An attacker could simply send us lots of useless packets; even though we throw the packets away, the work caused by interrupts drives our useful throughput to zero.
Denial of Service
Goal: The attacker wants to prevent the victim from doing any useful work.
This is possible because unknown work takes priority over useful work.
Key Idea: DON'T WASTE WORK! If you spend any effort on a packet or request, that packet should take priority over unknown or invalidated packets.
Denial of Service Bottlenecks:
- CPU
- Bus
- Memory
How to combat these attacks:
- Could the Network Interface Card (NIC) drop invalid packets? This might help; but then the attacker could send seemingly valid packets!
- NIC knows how many packets the CPU can handle and drops any excess packets? This can be implemented by making the DMA queue only as big as the CPU can handle.
- Interrupts and PIO are expensive so try polling the DMA instead. This can lead to a MLFFR up to 7 times better and avoids expensive PIO.
Polling
Let's consider what happens if we shift to a polling infrastructure instead. What polling issues do we get? Polling wastes CPU resources when the input rate is low.
What can be done? Poll less often at low rates -- but the cost is latency.
So why not Use a mixed system! Enable interrupts when input rate is low and switch to polling when input rate is high. This is probably the best solution.
Application Interface to the Network
The read() and write() functions serve as an application interface to the network.
- read(): read data from the network
- write(): write data to the network
Server Architectures:
A server is a program that responds to many possibly concurrent client requests. We discussed the server architectures before, with respect to the Flash Web server. Here's a review.
- Multi-Process (MP). Avoids blocking the server on clients by assigning one process per client. Bottlenecks in context switches, process overhead, and memory (for the many processes). If the client blocks, only that process blocks. This requires that we clean up processes that are wait too long for dead or malicious clients.
- SPED (Single Process Event Driven)/AMPED. Non-blocking client I/O. Read or write can partially succeed: read returns only available data and write writes only data that there's room for.
If 5 bytes are need and only 4 bytes are available:
1. Save the 4 bytes.
2. Read remaining byte when it becomes available -> need OS interface.
Non-blocking interfaces:
The select system call provided the earliest non-blocking interface.
int select (int max_fd, fd_set *read_fds, fd_set *write_fds, fd_set *x_fds, struct timeval *timeout);
Select uses bitmaps of interesting fd's: one for reads, one for writes, and the other to indicate error conditions. The system call blocks until and an "interesting event" occurs. The user then analyzes the bitmaps to determine which file descriptors are ready for read or write!
As high performance servers were being developed, they were profiled. It was determined that the operating system implementation of 'select' was actually a bottleneck!
Let's take a look at an overview of the system implementation of the select() system call:
1. Context switch into the kernel
2. Copy memory pages into kernel space to ensure they are available to the system call *
3. Traverse the bitmaps up to identify interesting descriptors *
4. Add current process to the wait queue associated for each interesting file descriptor.*
5. Sleep
6. Re-traverse bitmaps to ensure that file descriptors that aren't ready are marked as such *
7. Copy memory pages back to user space *
One problem with with 'select' is that copying memory pages into and out of the kernel is expensive. (Steps 2 and 7 do this.) An even more major problem is that the system must iterate through bitmaps to determine interesting file descriptors. Even though the interface provides 'max_fd' as a cutoff for processing (file descriptors larger than max_fd are automatically uninteresting), a lot of effort is wasted if the only interesting file descriptor has a high number. Furthermore, the common case is for the "interesting" sets to remain largely the same in between calls to 'select'. This means that we pay the cost again and again to traverse bitmaps and add processes to wait queues (Steps 3 and 4), when it would be faster to do this work just once.
How can these issues be addressed?
- Report all file descriptors as interesting by default? No, this is not a very helpful interface.
- Separate the setup of interesting things from actual blocking call --> kevent / epoll
Let's take a look at kevent, which supersedes select in modern FreeBSD distributions. (Linux has a similar interface, called epoll. We used slightly different syntax in class.)
- First, the user creates an event queue, which will remember a
list of interesting events.
int kq = kqueue();
- Next, the user adds interesting events to the event queue, using
the
keventsystem call. The syntax for this is a little baroque, but you get the idea:// Indicate interest in read events on file descriptor 'fd'. struct kevent kev; int r; EV_SET(&kev, fd, EVFILT_READ, EV_ADD, ...); r = kevent(kq, &kev, 1, ...); assert(r >= 0);
The user can remove or change events attached to the kqueue in a similar way. - Finally, when the user wants to wait for an event, they call
keventwith different parameters:struct kevent kev[20]; int n = kevent(kq, NULL, 0, &kev[0], 20, /* timeout ptr */); // Up to 20 interesting events have been copied into the 'kev' array. // 'n' is the number of events that happened.
The kevent interface eliminates the problems associated with parts 2,3,4 of the select implementation by allowing the user to set up interesting events separately from the blocking call. This is helpful if the set of interesting file descriptors does not change a lot in between blocking calls. Kevent also simplifies the copying of memory back into user space because only interesting file descriptors are returned.
Be mindful when you are designing interfaces. Simple changes in interface design such as moving between select and kevent can actually improve the performance of a busy server by a factor of 2!